Homo digitalis - cyfrowy ślad człowieka

W taki sposób redaktorzy miesięcznika „Wired” zaczęli eksperyment, który miał odpowiedzieć na pytanie - czy w dzisiejszym świecie nowoczesnych technologii i Internetu można zniknąć bez śladu. Za głowę Ratliffa wyznaczona została nagroda 5 tys. dolarów. W pościg ruszyło kilkuset czytelników. Tropili zbiega, analizując jego numery IP, prześwietlając życie na podstawie informacji, które znaleźli o nim w Internecie. Wymieniali się wiadomościami na Twitterze i Facebooku, a tysiące osób obserwowało te zmagania w sieci.
Ratliff został zdemaskowany w Nowym Orleanie, w dwudziestym siódmym dniu podróży.

Namierzono go dzięki śladom cyfrowym. Nie zmienił zdjęcia na utworzonym specjalnie fałszywym profilu na Facebooku. Wykorzystał to były programista Microsoftu z Seattle, który przystąpił do polowania kilka dni po starcie. Wiedząc, że poszukiwany odwiedza strony poświęcone pościgowi, napisał program, który miał go znaleźć wśród ich gości. Szybko wyodrębnił kilka podejrzanych profili. W tym Jamesa Donalda Gatza, który okazał się fałszywym profilem dziennikarza. Gdy programista spojrzał na zamieszczone tam zdjęcie, miał pewność, że to „zaginiony” dziennikarz. Od tamtej pory Jeff śledził IP Jamesa Gatza na Facebooku. Podglądał też Twitter pod adresem @jdgatz. Następnie w Nowym Orleanie namierzył pizzerię, na której stronę wszedł poszukiwany - i tam ostatecznie „schwytał zbiega”.
Anonimowość pozorna
W czasach tzw. big data (2) każdy człowiek-mieszkaniec cyberprzestrzeni pozostawia po swojej aktywności tropy, nazywane cyfrowym śladem lub cieniem. Cyfrowy świat jest naturalnym środowiskiem życia owego nowego gatunku człowieka, zwanego czasem homo electronicus lub digital native. Żyjąc w swoim środowisku, cybertubylec generuje dane, które trafiają do Internetu, do baz danych, do chmur obliczeniowych. I w tym środowisku żyją już sobie własnym życiem. Trop ten powstaje nie tylko poprzez bezpośrednie działania człowieka, ale również przetwarzanie informacji o nim przez przeróżne narzędzia i systemy. Inaczej mówiąc, każda osoba nabywa i staje kształtuje swój cyfrowy profil dokładnie opisujący jej zachowania.

Wraz z powstaniem Internetu ilość wytwarzanych i jednocześnie gromadzonych danych zaczęła gwałtownie rosnąć. Fenomen ten na całym świecie został określony jako big data. Termin ów wykorzystuje się do opisania ogromnej ilości danych analizowanych przez wielkie organizacje, takie jak Google lub projekty badawczo-naukowe NASA. Rozmaite instytucje, np. finansowe, dysponują bardzo dużymi własnymi zasobami danych, dotyczących zachowań zakupowych oraz nawet bardzo wrażliwych informacji odnoszących się do kondycji finansowej klientów. W przypadku zdobycia kolejnych danych banki mają bardzo podobne możliwości w stosunku do innych firm. Wystarczy użyć danych lokalizacyjnych z mobilnej aplikacji bankowości internetowej i poprosić klienta o zgodę na udostępnienie profili na portalach społecznościowych w celu otrzymania lepszej oferty, aby uzyskać potrzebne informacje.

Każdego ranka, po uruchomieniu przeglądarki i przejściu na dowolną stronę internetową, w milisekundach między klikaniem a pojawieniem się na ekranie wiadomości, przekazywane są informacje, pozostawiające trwały ślad po obecności każdego użytkownika. Dane z tej jednej wizyty są wysłane nawet do kilkunastu różnych firm. Prawie natychmiast mogą one zarejestrować tę wizytę.
Badania wykazały, że mniej więcej tylko połowa naszego cyfrowego śladu dotyczy indywidualnych działań, robienia zdjęć, wysyłania e-maili, aktywności w serwisach społecznościowych (3) lub tworzenia cyfrowych połączeń głosowych. Reszta odnosi się do informacji personalnych danej osoby, dokumentacji finansowej, nazwisk na listach mailingowych, internetowych historii przeglądania stron, a także obrazów zapisanych przez kamery bezpieczeństwa w portach lotniczych i ośrodkach miejskich.
W świecie cyfrowym każdy jest skojarzony z dziesiątkami znaczników, znanych pod nazwą cookies, opisujących jego zachowanie, a zarazem nadających mu e-tożsamość. Wskaźniki te pozwalają zbieraczom danych na stałą obserwację. Pliki cookies nie powiązują jednak zgromadzonych danych z tożsamością osoby w świecie realnym. Dziennik „Wall Street Journal” opublikował kilka lat temu raport dowodzący, że Internet przekształcił się w miejsce, w którym ludzie są anonimowi jedynie wówczas, gdy chodzi o nazwiska.
Tożsamość jako waluta
Dobrym przykładem może być działający w Stanach Zjednoczonych serwis Lenddo. Ocenia on zdolność kredytową klientów banków na podstawie
ich osobowości online. W tej ocenie brane są pod uwagę takie czynniki i parametry, jak informacje, które zamieszczamy w sieci, rodzaj słuchanej muzyki, krąg znajomych itd. I tak np. fani hip-hopu mają niższy rating niż miłośnicy muzyki klasycznej. Poza tym liczy się nie tylko to, co sami robimy, ale także to, jak zachowują się ci, których mamy w swoim kręgu znajomych. Jeśli nasz facebookowy przyjaciel ma/miał problem ze spłatą swojego zadłużenia, serwis automatycznie obniża także naszą wiarygodność kredytową (4).
Podobne mechanizmy związane z internetową reputacją wykorzystuje niemiecki Kreditech. Oprócz danych pochodzących z serwisów społecznościowych, bierze się tu pod uwagę tak szczegółowe kwestie, jak np. to, czy komputer, z którego wypełnialiśmy wniosek o pożyczkę, znajduje się w miejscu, które podaliśmy jako miejsce zamieszkania lub pracy. Zbliżony model działania stosuje kolejna firma z rynku mikropożyczek - Kabbage. Dostarcza ona kapitał obrotowy e-handlowcom, a przy ocenie wiarygodności klientów bierze pod uwagę historię dokonywanych transakcji w systemach szybkich płatności, takich jak PayPal czy serwisy aukcyjne - bada również dane z ok. 8 tys. innych źródeł, m.in. pliki cookies z portali zakupowych czy powiązania w sieci LinkedIn.
Według raportu „Harvard Business Review Polska” - „Big Data: Przełom w zarządzaniu firmą” - każdego dnia ponad trzy miliardy internautów i instytucjonalnych użytkowników sieci generuje niezliczoną liczbę danych. Tylko jedna amerykańska sieć sklepów Walmart gromadzi co godzinę ponad 2,5 petabajta danych o transakcjach swoich klientów. Żeby zrozumieć ogrom tych zasobów, wystarczy powiedzieć, że 1 PB to ok. 20 mln szafek wypełnionych dokumentami. Ludzkość, przenosząc coraz więcej aktywności do cyfrowego świata, jeszcze nigdy nie tworzyła informacji tak szybko, w tak masowy sposób.
Jak wynika z badań UE z 2011 r., 70% Europejczyków obawia się, że ich dane będą nadużywane. Czują, że nie są w stanie w pełni kontrolować krążących informacji. Taki stan rzeczy nie tylko wprowadza niepokój wśród społeczeństwa, ale burzy zaufanie do samych usług internetowych, w konsekwencji utrudniając pełne wykorzystanie możliwości, jakie daje firmom analiza big data. To jednak problem firm. Przeciętny człowiek martwi się o swoją własną prywatność.
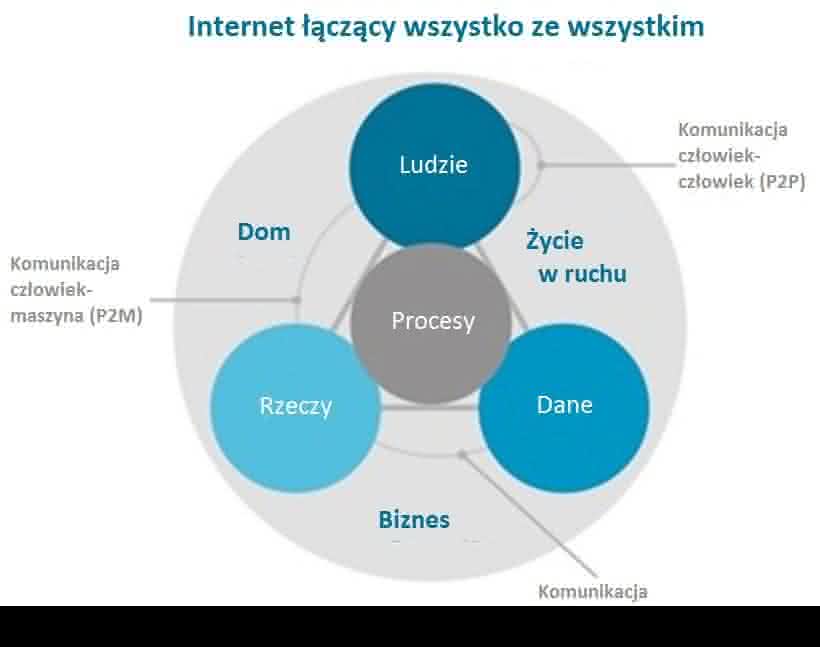
Źródłem zasobów big data są nie tylko tradycyjne narzędzia komunikacji internetowej - komputery, laptopy, smartfony - ale także przedmioty codziennego użytku: karty płatnicze (pokazują, co, gdzie, kiedy i za ile kupujemy), bramki autostradowe i miejski monitoring (gdzie i jak jeździmy), gadżety mierzące parametry fizjologiczne podczas aktywności fizycznej (zapisują stan naszego zdrowia) itd. Tym, do czego w konsekwencji ostatecznie zmierzamy, jest Internet Rzeczy (Internet of Things, IoT), który spowoduje, że obecne ilości wytwarzanych, przechowywanych i transferowanych w cyfrowym świecie danych przestaną być postrzegane jako ocean informacji, a staną się zaledwie jego niewielką kroplą. Związany z tym etapem rozwoju postęp (miniaturyzacja urządzeń hardware’owych i rozwój aplikacji, czyli rozwiązań software’owych) spowoduje, że Internet stanie się wszechobecny i połączy wszystko ze wszystkim (5), co zresztą przełoży się na uproszczenie wielu codziennych czynności (np. zakupów) i stworzy nowe możliwości rozwoju medycyny (np. telemedycyna), energetyki (np. smart grid) czy transportu (np. connected car).
Tożsamość i wizerunek, które weszły do tego obiegu, przestają być więc naszą prywatną własnością, a stają się rodzajem nowej waluty. Pozostawiony cyfrowy ślad jest analizowany przez wiele firm, tak aby w jak najlepszym stopniu dopasować reklamę do potrzeb potencjalnego klienta, a następnie sprawdzić, czy i jak to rzeczywiście działa. Miejsce reklamy dostosowywane jest wręcz specjalnie dla oczu danej osoby, a dane dodawane są do archiwum o osobie przeglądającej daną stronę internetową. Nie ma żadnych informacji o centrum wymiany danych.
Tylko AI to ogarnie
Śmiałe twierdzenia o zalewie danych owocują np. takimi porównaniami, że w ciągu dwóch dni produkujemy tyle informacji, co cała ludzkość do 2003 r., lub że w ciągu ostatnich dwóch lat wyprodukowaliśmy 90% istniejących danych. Cywilizacja ziemska w bardzo krótkim czasie przeszła od etapu niedoboru informacji do jej wszechogarniającego nadmiaru. Według szacunków Cisco, zawartych w Global Cloud Index Study, do 2018 r. IoT wytwarzać będzie rocznie ponad 400 zettabajtów danych. Przy tak gigantycznych zasobach pojawia się potrzeba nadzwyczajnych narzędzi do analizy owych gór big data.
Obecnie sądzi się, że zadanie to przejmie wkrótce sztuczna inteligencja (AI, artifficial intelligence). Zastąpienie ludzi w zadaniach analizy ogromnych zasobów zmiennych i różnorodnych danych, których przetwarzanie jest trudne, ale jednocześnie wartościowe, byłoby chyba najważniejszym praktycznym zastosowaniem systemów AI.
Niedawno powstałe w Massachusetts Institute of Technology (MIT) narzędzie o nazwie Data Science Machine już teraz radzi sobie z analizą znacznie lepiej niż ludzie. Ta wersja AI być może kiedyś przejmie władzę nad światem i zniewoli ludzkość, na razie jednak zajmuje się stosunkowo przyziemnymi problemami, np. przewidywaniem, którzy studenci wycofają się z których kursów na MIT. Dokonuje tego na podstawie czasu wykonywania przez nich zadań wyznaczonych przez wykładowców.
Data Science Machine służy wyłącznie do analizy danych. Twórcy rozwiązania wystawili nawet swoją sztuczną inteligencję w trzech konkursach z obszaru nauk o analizie danych. W rywalizacji, w której uczestniczyło 906 zespołów, AI z MIT wyprzedziła 615 z nich. W kolejnym była w 94-96% tak dokładna, jak ludzie. W trzecim jej dokładność wyniosła 87%, jednak do wyniku tego doszła w ciągu dwunastu godzin, podczas gdy ludzkie zespoły potrzebują na takie samo zadanie miesięcy.
Wychodzi więc na to, że „Internet danych” będzie zarazem królestwem sztucznej inteligencji. Trudno przewidzieć, jakie to może mieć konsekwencje dla ludzkości - ale to już nieco inna historia.
Zapraszamy do lektury całego Tematu Numeru w najnowszym wrześniowym wydaniu miesięcznika "Młody Technik".