Czego się AI nie nauczy, tego Terminator nie będzie umiał

Jak działa "uczenie maszynowe", całkiem nieźle pokazuje przykład sztucznej inteligencji AlphaGo stworzonej przez zespół DeepMind Google’a. Z mistrzem gry w Go jej twórcy nie mieliby najmniejszych szans, natomiast dzieło ich pracy owego mistrza pokonuje. Dzieje się tak dlatego, że maszyna "sama" nauczyła się grać na wysokim poziomie, odbywając dziesiątki tysięcy partii z rzeczywistymi i wirtualnymi zawodnikami. Zresztą, jeśli wierzyć doniesieniom z prasy naukowej, wspomniany DeepMind nie potrzebuje już swoich twórców, przynajmniej jeśli chodzi o edukację - zaczął się bowiem sam rozwijać i doskonalić, samodzielnie pozyskując potrzebne mu informacje. "Ten komputer posiadł zdolność samodzielnego uczenia się na wcześniejszych przykładach i wyrabiania w sobie logicznych nawyków" - ogłosili główni technolodzy projektu DeepMind - Alex Graves i Greg Wayne.
Stało się to możliwe dzięki wdrożeniu systemu Differential Neural Computer (DNC), który przy wykorzystaniu sieci neuronowej jest w stanie sam pozyskiwać potrzebne mu fragmenty wiedzy i wbudowywać je w odpowiednie miejsca sztucznej inteligencji, starając się robić to jak najszybciej i najbardziej logicznie. Działa więc podobnie jak ludzki mózg. Specjaliści Google pokazali też, jak to działa w praktyce. Kiedy systemowi DNC objaśniono, na czym polega drzewo genealogiczne, sztuczna inteligencja natychmiast je zbudowała, odnajdując w sieci wszelkie możliwe związki między wybranymi ludźmi oraz na bieżąco optymalizując i odświeżając swoją pamięć, żeby w przyszłości robić to samo jeszcze szybciej i skuteczniej!
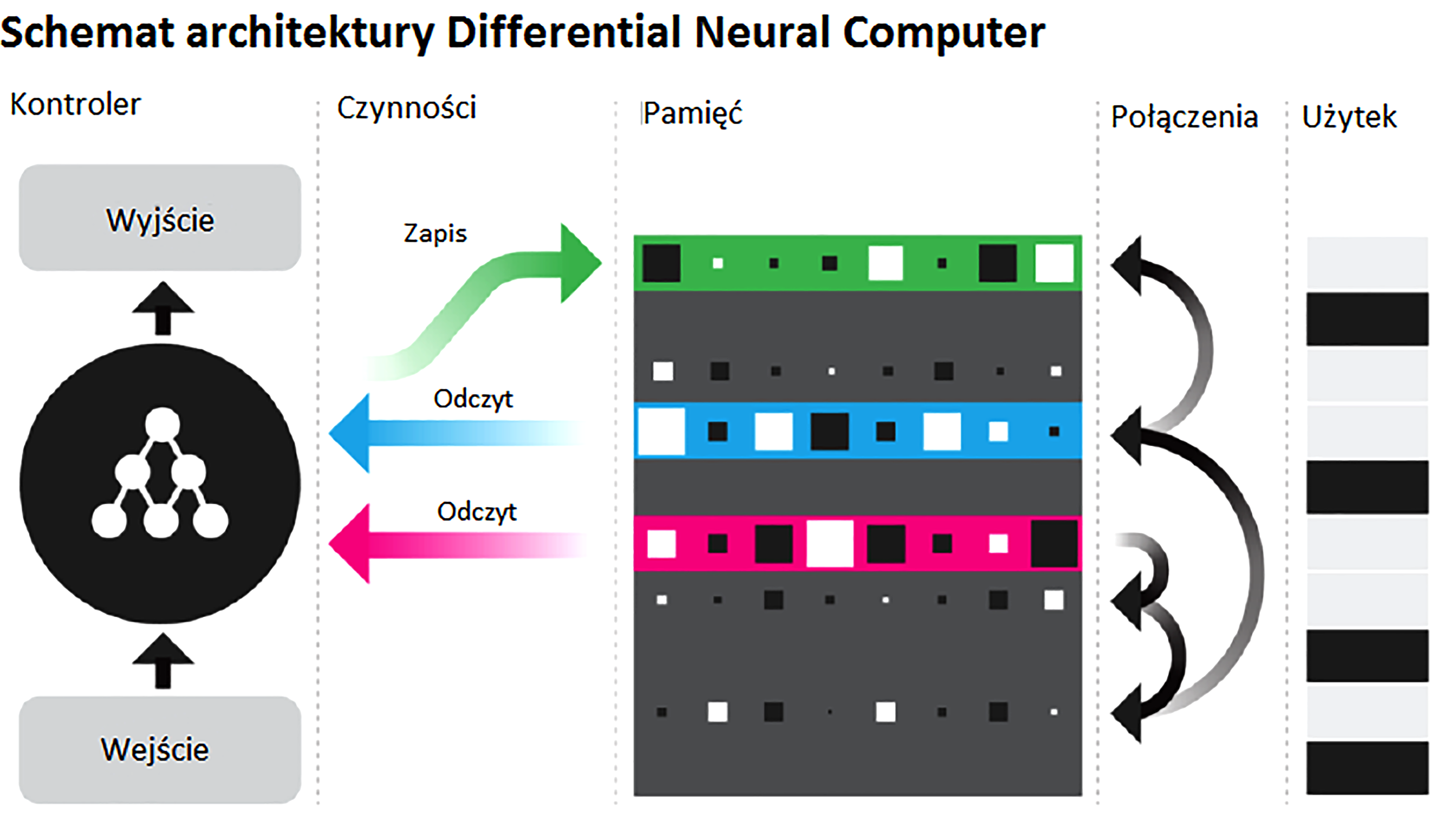
Schemat architektury Differential Neural Computer
To nie wszystko. Systemowi DNC pokazano następnie mapę londyńskiego metra, a ten natychmiast zaczął proponować optymalne połączenia i nowe rozwiązania usprawniające komunikację między poszczególnymi stacjami. Robił to jednak nie jak zwykły komputer, mozolnie analizujący wszystkie możliwe warianty, tylko działał na podstawie zapamiętanych prawidłowości i logicznych powiązań, które sam wykrył i dopasował do bieżącej sytuacji.
Google jest prawdziwym liderem badań i rozwoju technik uczenia maszynowego AI. Pod koniec listopada ubiegłego roku pojawiła się wiadomość, że sztuczna inteligencja Google’a uczy się tłumaczenia pomiędzy językami, których nie zna. Nazywa się to zero-shot translation i działa dzięki narzędziu o nazwie Google Neural Machine Translation. W przeciwieństwie do dobrze znanego internautom translatora, nie wymaga ono "znajomości" języków przez system.
Logo Google związane z tłumaczeniami na różne języki
Jednocześnie wiadomo, że Google tworzy w swoim internetowym translatorze nowy mechanizm tłumaczenia tekstów. Rozwiązanie oparte na sztucznej inteligencji i sieciach neuronowych ma przekładać teksty na inny język z dokładnością zbliżoną do zawodowych tłumaczy. O nowym rozwiązaniu doniósł serwis Quartz, opierając się na własnych informacjach.
Dostępny obecnie internetowy translator Google oparty jest na analizie poszczególnych zdań. Algorytm dzieli zdanie na poszczególne słowa, tłumaczy je na podstawie słownika i próbuje dopasować do siebie w języku, w którym ma powstać tłumaczenie. Natomiast nowe rozwiązanie będzie wykorzystywało w działaniu sztuczną inteligencję i sieci neuronowe. Zgodnie z zapowiedziami jedna z sieci ma na podstawie słownika analizować całe zdanie i określać, co ono oznacza, druga natomiast wygeneruje na tej podstawie przetłumaczony tekst wyświetlany na ekranie. Google zakłada, że nowe rozwiązanie będzie podczas tłumaczenia popełniać o 80% mniej błędów niż dostępny obecnie translator. Przeprowadzone testy wykazały, że przygotowywana metoda tłumaczenia w wypadku przekładu z hiszpańskiego na angielski osiągnęła 5 punktów w 6-punktowej skali, gdzie maksimum punktacji oznacza perfekcyjne tłumaczenie. Doświadczony tłumacz uzyskuje podobne wyniki. Obecny translator jest zaś w stanie osiągnąć poziom 3,6 punktu.
Sztuczne neurony dają radę
Historia sztucznej inteligencji zaczyna się na poważnie od perceptronu, wynalazku z lat 50. ubiegłego wieku, której głównym zadaniem było właśnie samokształcenie. Nazwa kojarzy się z jakimś urządzeniem - i słusznie, bo wynalazca, psycholog Frank Rosenblatt, początkowo myślał o maszynie zbudowanej na podobieństwo organizmów biologicznych i umiejącej się uczyć. Tak naprawdę chodzi jednak o pewien algorytm, który realizowano programowo, początkowo na uniwersalnym komputerze, a potem na komputerze z wyspecjalizowanymi peryferiami. Perceptron to algorytm klasyfikujący: uczy się jakieś klasy i daje odpowiedź, czy wejściowy zestaw danych do niej należy, czy nie. Pierwszy model zbierał dane z 400-pikselowego sensora optycznego i stwierdzał, czy widoczna figura geometryczna odpowiada wyuczonemu wzorcowi. Perceptron jest jednym z kilku rodzajów sztucznego neuronu - urządzenia o wielu wejściach i jednym wyjściu, które daje tylko jedną odpowiedź (najczęściej "tak" lub "nie").

Zwykle maszyny obliczeniowe pomagają w rozwiązywaniu problemów w inny sposób: człowiek określa reguły postępowania (program), a korzyść z użycia maszyny polega wyłącznie na tym, że ta nie popełnia błędów, nie męczy się i jest od nas szybsza. Ale zaprogramowany przez człowieka program może poradzić sobie wyłącznie z zadaniami, których metoda rozwiązania jest już znana. Uczenie się kojarzymy z procesem i zmianami, a algorytm - z czymś określonym z góry i niezmiennym.
Jest jednak wiele problemów, których nie umiemy rozwiązać. Mamy mnóstwo danych potrzebnych do udzielenia odpowiedzi, ale nie potrafimy znaleźć albo precyzyjnie opisać odpowiednich reguł postępowania. Przykładem może być zachowanie rynku powiązanych ze sobą dóbr i instrumentów finansowych. Intuicja podpowiada, że ich dotychczasowe zachowanie ma zasadniczy wpływ na ich zachowanie w najbliższej przyszłości. Danych jest jednak tak dużo, a zależności są tak zawiłe, że nie umiemy znaleźć wzoru pozwalającego przewidzieć tę przyszłość. Są też problemy dla człowieka banalne, ale trudne do opisania, np. rozpoznawanie kształtów na obrazach. Jesteśmy w stanie odróżnić zdjęcie kota od zdjęcia psa, ale nie znamy prostego programu, który pozwoliłby maszynie zrobić to samo.
I w tych właśnie sytuacjach możemy wykorzystać sieć neuronową, czyli uczący się algorytm, który metodą prób i błędów dojdzie do organizacji elementów pozwalającej na znalezienie odpowiedzi.
Wspomniany perceptron jest najprostszą siecią neuronową, złożoną z jednego sztucznego neuronu. Ma kilka wejść, do których przypisane są wagi, określające, jak wpływa wielkość z danego wejścia na wynik. Zestaw danych ze wszystkich wejść jest podstawiany do pewnego wzoru określonego przez programistę - w oryginalnym perceptronie było to dodawanie. Jeśli suma wszystkich wejść (z uwzględnieniem wag) przekroczy określony z góry próg, perceptron da odpowiedź pozytywną (logiczne 1), a jeśli nie - negatywną (logiczne 0). Łatwo zauważyć, że taki układ jest niewiele lepszy od zwykłych bramek logicznych. Dziś stosuje się inny rodzaj sztucznych neuronów, które dają odpowiedź w formie liczby rzeczywistej, czyli nie tylko 0 lub 1, ale dowolną liczbę pomiędzy.
Sieć neuronowa uczy się na przykładach - trzeba jej przedstawić jakąś liczbę już rozwiązanych przykładów. Tok uczenia sieci można zacząć od przypisania równych lub losowych wag każdemu wejściu. Sprawdzamy, czy odpowiedź sieci jest zgodna z pożądanym wynikiem, a następnie zmieniamy wagi tak, żeby wynik zbliżał się do pożądanej odpowiedzi. W pierwszym perceptronie z lat 50. XX wieku do regulacji wag służyły potencjometry, początkowo regulowane ręcznie. Mechanizm regulacji wag jest też jednak częścią sieci neuronowej, tzw. regułą uczenia, i działa automatycznie. Perceptron jako neuron pozostaje trudny w uczeniu, bo zmiany wielkości wejściowych lub wag mają skutek albo całkowity, albo zerowy - nie można obserwować, jak drobne zmiany przybliżają odpowiedź sieci do pożądanego wyniku.
Jeden sztuczny neuron ma niewielkie możliwości rozwiązywania problemów. Wiele neuronów można jednak połączyć w warstwy, gdzie jedna warstwa przekazuje wyniki kolejnej, aż do najwyższej, dającej odpowiedź.
Najprostsze sieci neuronowe podają informacje tylko w jednym kierunku - każdy neuron reaguje na jeden zestaw danych wejściowych tylko raz. Bardziej złożone sieci są rekurencyjne, co znaczy, że dane wychodzące z którejś z ukrytych warstw trafiają do jednej z poprzednich warstw. Sprzężenie zwrotne powoduje, że sieć po jakimś czasie osiąga stan równowagi i "decyduje się" na konkretną odpowiedź.
Struktura sieci (połączenia między neuronami) oraz mechanizm działania każdego neuronu (wzór, do którego podstawia się wielkości wejściowe) zwykle są określone z góry. Podstawową pamięcią sieci jest zestaw wag, parametrów określających stopień wpływu poszczególnych wejść na wynik danego neuronu. Sieci zazwyczaj mają dwa wykluczające się tryby pracy - tryb uczenia i tryb działania. W tym drugim nie zmieniają już wagi połączeń między neuronami; sieć daje tylko odpowiedzi, ale nie uczy się na każdym kolejnym przedstawionym przykładzie.
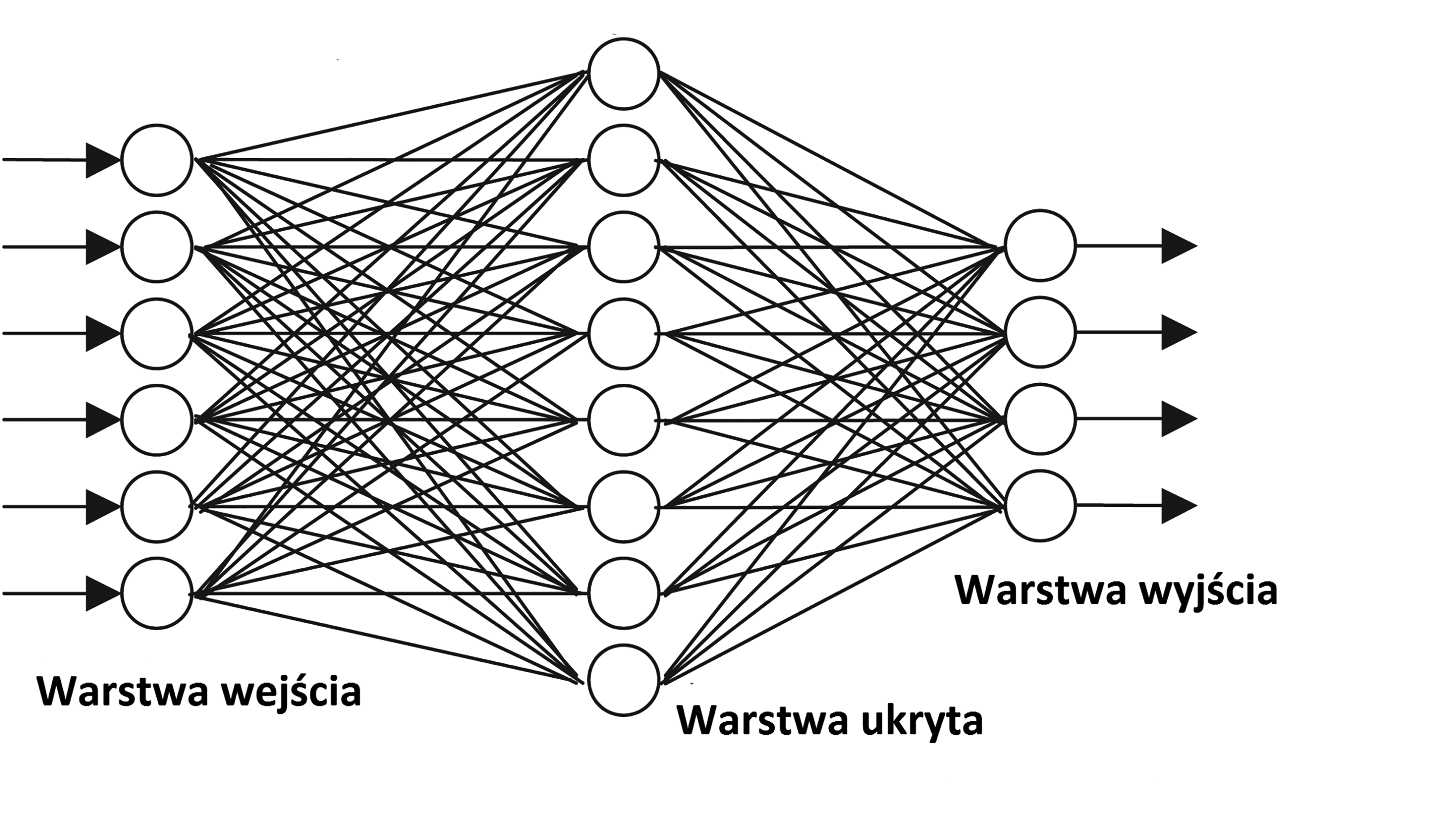
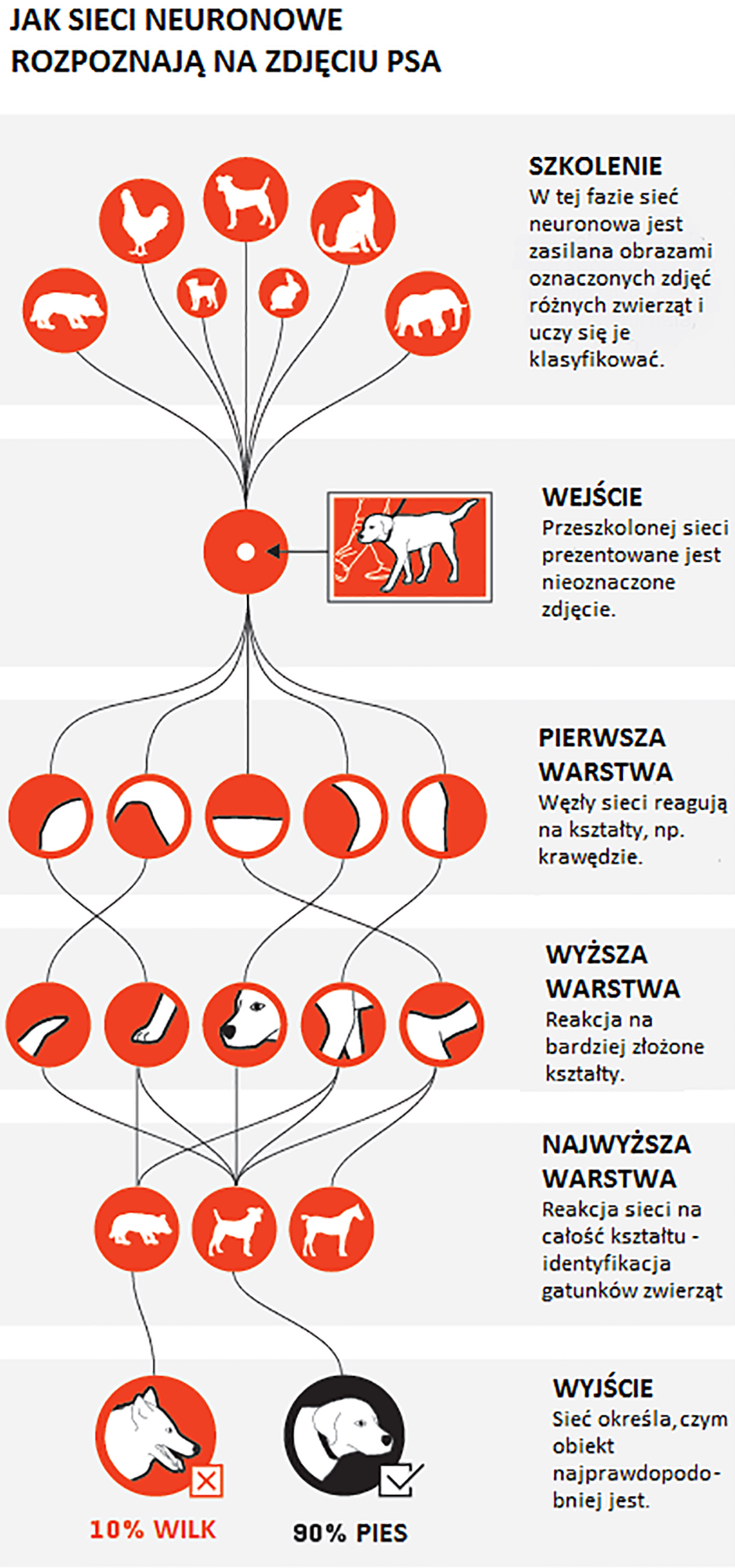
Proces uczenia może być nadzorowany przez człowieka, jeśli problem do rozwiązania jest w jakimś stopniu zrozumiały i spodziewamy się, jakie powinny być pośrednie kroki prowadzące do rozwiązania. Określa się wtedy, jakich cech sieć ma poszukiwać w zestawie danych wejściowych. Przykładowo, podczas rozpoznawania twarzy na obrazach sieci neuronowe trenuje się tak, żeby wcześnie wykrywały obszary o dużym kontraście, zwykle oznaczające obraz nosa i oczu.
Kiedy problem jest zbyt skomplikowany albo określone przez ludzi cechy prowadzą do niesatysfakcjonującego rozwiązania, można używać nienadzorowanego uczenia. Sieć ucząca się w taki sposób musi być odpowiednio złożona, wielowarstwowa, żeby mogła wykrywać w danych wejściowych abstrakcje wyższego rzędu. Ponieważ sieci uczone bez nadzoru nie dążą do zadanego wyniku, mają potencjał wykrywania prawidłowości i zależności, o których wcześniej nie wiedzieliśmy. To powoduje, że są użyteczne do analizy zjawisk, których model jest niedokładny albo niekompletny - a to można powiedzieć o prawie o wszystkich zjawiskach społecznych albo finansowych.
Ach te dzieci, czyli nadzieje i rozczarowania
Nauka kojarzy nam się głównie z dzieciństwem i właśnie dziecięcy sposób zdobywania wiedzy chcą wykorzystać do uczenia maszynowego specjaliści z Laboratory for Animate Technologies na Uniwersytecie w Auckland, w Nowej Zelandii. Program BabyX jest próbą odtworzenia w sensie dosłownym sytuacji dziecka uczącego się w szkole. Jak tłumaczy jeden z autorów programu, Mark Sagar: "Chcieliśmy stworzyć komputer, który może doświadczać, ma wyobraźnię, a także coś na kształt własnej egzystencji."
Mark Sagar słynie z budowania symulacji ludzkiej twarzy, które można zobaczyć m.in. w filmach "Avatar" czy "King Kong". Dziecięca twarz BabyX została wykreowana za pomocą programów 3D do budowy animacji twarzy, podobnie jak inne obrazy, które pojawiają się w grach i filmach. Zespół Sagara stworzył też uproszczone modele niektórych części ludzkiego mózgu (np. hipokampu), które po połączeniu ze sobą są w stanie wykonywać dość złożone operacje. Oznacza to, że BabyX ma w swojej "czaszce" algorytmy, które działaniem naśladują ludzkie neurony i złożone z nich struktury mózgowe.
Taka konstrukcja "mózgu" programu pozwala mu słyszeć i uczyć się, czemu towarzyszą niezwykle naturalna mimika i emocje. Na filmie widać np., że sztuczne dziecko zespołu Sagara reaguje strachem na dźwięk głośnego uderzenia w ręce. Dzieje się tak dlatego, że konkretnej informacji, np. głośnemu dźwiękowi, model mózgu przypisuje konkretny układ "mięśni twarzy" dziecka opisany na specjalnych, widocznych na filmie suwakach. Co więcej, BabyX widzi. Inżynierowie z Auckland zasymulowali działanie komórek ludzkiego oka oraz cały towarzyszący patrzeniu proces mózgowy. Poza systemem neuronowym BabyX wspiera się innymi systemami, które pozwalają na rozpoznawanie emocji, mimiki i twarzy ludzi. Dlatego to dziecko może w tak przekonujący sposób reagować na siedzące przed komputerem osoby czy oglądać obrazki z książeczki dla dzieci.

Uczy się ono w sposób podobny do ludzkiego. Programiści pokazują mu dużą liczbę przykładów i pozwalają, aby samo określiło algorytm, którym opisze dany przedmiot. Przykładowo, po przejrzeniu wystarczająco dużej liczby szczeniaków tworzy się algorytm, który określa, że jeżeli coś jest brązowe, małe i ma uszy o konkretnym kształcie, to może być pieskiem. Z każdym kolejnym przykładem algorytm staje się coraz bardziej precyzyjny, aż w końcu BabyX potrafi bezbłędnie określić, co jest pieskiem, a co człowiekiem.
Ciekawe, że podobnie jak w przypadku dzieci, zbudowane przez speców od AI maszyny potrafią także zawieść wielkie oczekiwania rodziców. O takim rozczarowaniu dowiedzieliśmy się od zespołu naukowców z japońskiego Narodowego Instytutu Informatyki. Nosił się on z zamiarem wysłania swojej AI o nazwie "Todai" na Uniwersytet Tokijski, ale zmuszony został porzucić ten pomysł. Projekt, o którym pisaliśmy swego czasu w "MT", prowadzony jest od 2011 r. System osiągał regularnie, z roku na rok, coraz lepsze wyniki. Jednak w 2016 r. okazało się, że nie poprawił wyniku swojego poprzedniego testu. Naukowcy uznali więc, że do 2022 r., który miał być rokiem rozpoczęcia nauki AI na prestiżowej uczelni, nie uda się osiągnąć rezultatów wymaganych na egzaminie wstępnym.
Noriko Arai, członkini zespołu, powiedziała wprost, że AI nie radzi sobie z pytaniami wymagającymi rozpoznania znaczenia w szerszym kontekście. "Maszyny wciąż nie opanowały ludzkich zdolności krytycznego myślenia i umiejętności rozwiązywania problemów, więc nie ma obaw, że szybko zabiorą nam naszą pracę", podsumowała.Zdjęcia: