Liczba zastosowań i znaczenie interfejsów głosowych szybko rośnie

Alexa, obecna dzięki głośnikom Echo (1) i innym gadżetom w dziesiątkach milionach domów w USA, zaczyna nagrywać po usłyszeniu swojej nazwy lub "słowa wywołującego" wypowiedzianego przez użytkownika. Oznacza to, że nawet jeśli wyraz "Alexa" padnie w reklamie telewizyjnej, urządzenie może zacząć zapis. To właśnie wydarzyło się w tym przypadku, utrzymują przedstawiciele firmy Amazon, dystrybuującej ów sprzęt.
"Dalszy tok rozmowy został zinterpretowany przez asystenta głosowego jako polecenie wysłania wiadomości", napisała firma w oświadczeniu. "W pewnym momencie Alexa zapytała głośno: 'Do kogo?’;Dalszy przebieg rodzinnej pogawędki o parkiecie z drewna liściastego miał zostać zrozumiany przez maszynę jako pozycja na liście kontaktów klienta." Takiego przynajmniej zdania jest Amazon. Tłumaczenie sprowadza się więc do zajścia serii niefortunnych zdarzeń.
Niepokój jednak pozostaje. Bo niby z jakiej racji w domu, w którym czuliśmy się do tej pory swobodnie, mamy wprowadzać jakikolwiek "reżim głosowy", uważać na to, co mówimy, co nadaje telewizja i oczywiście - co mówi do nas ten nowy mały głośniczek na komodzie.
Niemniej, pomimo niedoskonałości technologii i obaw o prywatność, wraz z rosnącą popularnością urządzeń takich jak Amazon Echo, ludzie zaczynają przyzwyczajać się do idei interakcji z komputerami za pomocą głosu.
Jak wskazywał podczas swojej sesji AWS re:Invent, pod koniec 2017 r., Werner Vogels, dyrektor ds. technologii w Amazonie, do tej pory technologia ograniczała nasze możliwości interakcji z komputerami. Słowa kluczowe wpisujemy do Google’a za pomocą klawiatury, ponieważ jest to wciąż najbardziej powszechny i łatwy sposób, w jaki jesteśmy w stanie wprowadzać do maszyny informacje.
- Interfejsy do systemów cyfrowych przyszłości nie będą już jednak skoncentrowane na maszynach lecz na człowieku - zauważył Vogels. - Możemy budować ludzkie naturalne interfejsy z systemami cyfrowymi, a wraz z tym całe nasze środowisko stanie się aktywne.
Wielka czwórka
Korzystając z wyszukiwarki Google na telefonie, z pewnością już dawno zauważyliśmy tamże znak mikrofonu z zachętą do mówienia. To Google Now (2), za pomocą którego można podyktować wyszukiwarce zapytanie, wpisać wiadomość za pomocą głosu itd. W ostatnich latach Google, Apple i Amazon znacząco udoskonaliły technologie rozpoznawania głosu. Głosowi asystenci, tacy jak Alexa, Siri czy Google Assistant, nie tylko rejestrują głos, ale rozumieją także to, co się do nich mówi i odpowiadają na pytania.

Google Now jest dostępny za darmo dla wszystkich użytkowników systemu Android. Aplikacja potrafi np. nastawić budzik, sprawdzić prognozę pogody i trasę na mapach Google’a. Konwersacyjne rozwinięcie Google Now stanowi Asystent Google’a (Google Assistant) - wirtualna pomoc dla użytkownika sprzętu. Jest dostępny przede wszystkim na urządzeniach mobilnych i inteligentnych urządzeniach domowych. W przeciwieństwie do Google Now, może angażować się w dwukierunkowe wymiany zdań. Asystent zadebiutował w maju 2016 r., jako część aplikacji Messaging App Allo Google, a także w głosowo aktywowanym głośniku Google Home (3).

System IOS także ma swojego wirtualnego asystenta, Siri, czyli program będący częścią systemów operacyjnych firmy Apple - iOS, watchOS, tvOS homepod oraz macOS. Siri zadebiutowała wraz z systemem operacyjnym iOS 5 oraz smartfonem iPhone 4s w październiku 2011 r., podczas konferencji "Let’s Talk iPhone".
Oprogramowanie opiera się na interfejsie konwersacyjnym: rozpoznaje naturalną mowę użytkownika (od wersji systemu iOS 11 możliwe jest również ręczne wpisywanie komend), odpowiada na pytania i wykonuje zadania. Dzięki implementacji nauczania maszynowego asystent z czasem analizuje osobiste preferencje użytkownika, w celu zapewnienia bardziej dopasowanych wyników i rekomendacji. Siri wymaga stałego połączenia z Internetem - głównymi źródłami informacji są tu serwisy Bing i Wolfram Alpha. W wersji oprogramowania iOS 10 wprowadzono obsługę rozszerzeń firm trzecich.
Kolejna z wielkiej czwórki jest Cortana. To inteligentny osobisty asystent stworzony przez Microsoft. Obsługują go platformy Windows 10, Windows 10 Mobile, Windows Phone 8.1, Xbox One, Skype, Microsoft Band, Microsoft Band 2, Android oraz iOS. Cortanę po raz pierwszy zaprezentowano podczas konferencji Microsoft Build Developer, w kwietniu 2014 r. w San Francisco. Nazwa programu pochodzi od imienia postaci występującej w serii gier "Halo". Cortana dostępna jest w języku angielskim, włoskim, hiszpańskim, francuskim, niemieckim, chińskim i japońskim.
Użytkownicy wspominanego już programu Alexa również muszą się liczyć z ograniczeniami językowymi - cyfrowy pomocnik posługuje się na razie tylko angielskim, niemieckim, francuskim i japońskim.
Wirtualny asystent firmy Amazon po raz pierwszy zastosowany został w inteligentnych głośnikach Amazon Echo i Amazon Echo Dot, zaprojektowanych przez Lab126 Amazona. Umożliwia interakcję głosową, odtwarzanie muzyki, generowanie list rzeczy do zrobienia, ustawianie alarmów, strumieniowe przesyłanie podcastów, odtwarzanie audiobooków oraz dostarczanie informacji o pogodzie, ruchu drogowym, sporcie i innych newsów w czasie rzeczywistym, np. wiadomości (4). Alexa umie sterować kilkoma inteligentnymi urządzeniami, tworząc system automatyki domowej. Może też posłużyć do robienia wygodnych zakupów w sklepie Amazona.
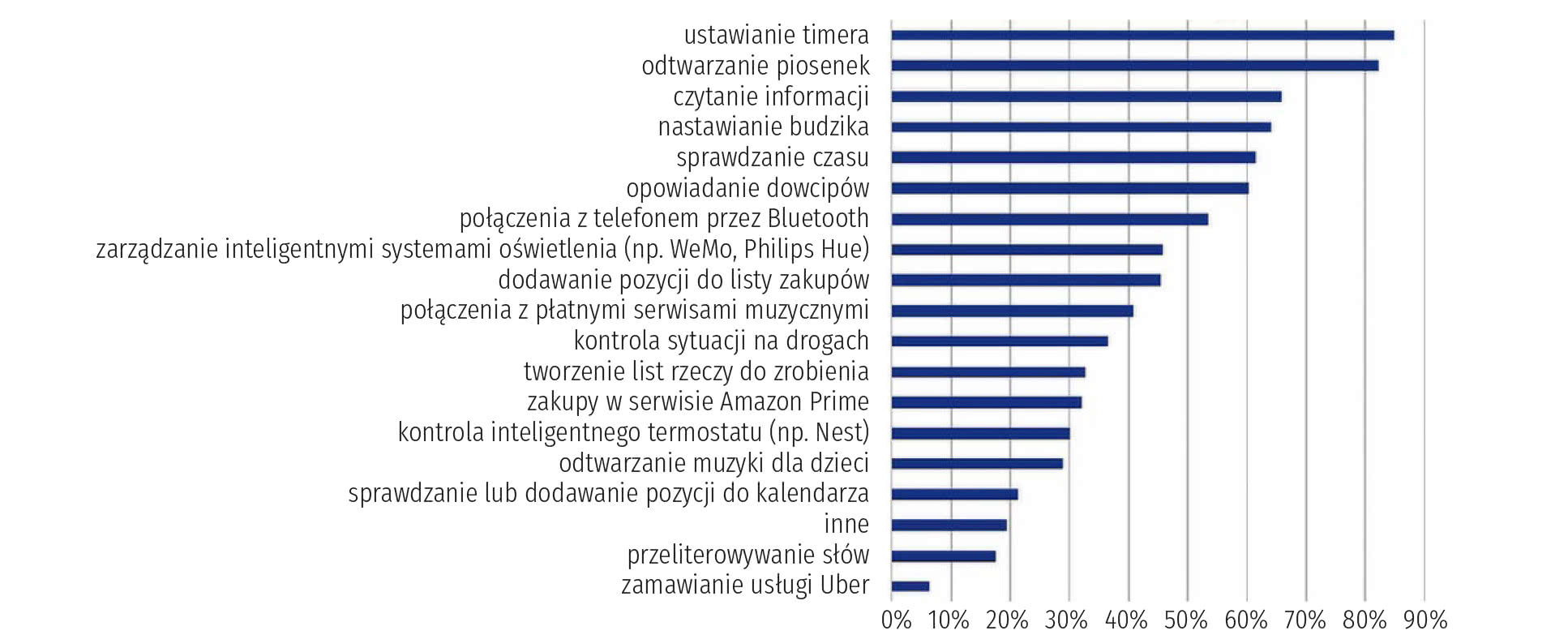
Użytkownicy są w stanie rozszerzyć możliwości Alexy, instalując jej "umiejętności" (skills), czyli dodatkowe funkcje opracowane przez zewnętrznych dostawców, w innych ustawieniach częściej nazywane aplikacjami, takie jak programy pogodowe i audio. Większość urządzeń z Alexą pozwala na aktywację wirtualnego pomocnika za pomocą hasła budzącego, tzw. wake-word.
Amazon zdecydowanie dominuje obecnie na rynku inteligentnych głośników (5). Do czwórki liderów próbuje dołączyć IBM, który wprowadził w marcu 2018 r. nową usługę, Watson Assistant, przeznaczoną dla firm, które chcą same budować wirtualne systemy asystenckie aktywowane głosowo. Na czym miałaby polegać przewaga rozwiązania IBM? Jak twierdzą przedstawiciele firmy, przede wszystkim na daleko większych możliwościach personalizacji i ochronie prywatności.

Po pierwsze, Watson Assistant nie ma żadnego narzuconego znaku towarowego. Firmy mogą na tej platformie tworzyć własne rozwiązania i oznaczać je swoją marką.
Po drugie, mogą szkolić swoje systemy asystenckie, używając własnych zestawów danych, przy czym, zdaniem IBM, w tym systemie łatwiej jest dodawać funkcje i polecenia niż w innych technologiach VUI (Voice User Interface).
Po trzecie, Watson Assistant nie przekazuje IBM informacji na temat aktywności użytkowników - twórcy rozwiązań na platformie mogą zachować cenne dane tylko dla siebie. Tymczasem wszyscy, którzy budują urządzenia np. z Alexą, muszą się liczyć z tym, że ich cenne dane trafią ostatecznie do Amazona.
Watson Assistant ma już na koncie kilka implementacji. System wykorzystała np. firma Harman, tworząca asystenta głosowego dla koncepcyjnego samochodu Maserati (6). Na lotnisku w Monachium asystent IBM zasila robota Pepper, oferującego gościom wskazówki dotyczące poruszania się. Trzeci przykład to firma Chameleon Technologies, w której technologia głosowa zasila inteligentny licznik domowy.

Warto dodać, że podstawowa technologia również tutaj nie jest nowa. Asystent Watson składa się z funkcji szyfrowania istniejących produktów IBM - Watson Conversation i Watson Virtual Agent, a także interfejsów API, przeznaczonych do analizy języka i rozmów.
Firma Amazon nie tylko jest liderem inteligentnych technologii głosowych, ale przekuwa to w bezpośrednią działalność biznesową. Niektóre firmy eksperymentowały jednak z integracją Echo znacznie wcześniej. Sisense, spółka z branży BI i narzędzi analitycznych, już w lipcu 2016 r. wprowadziła integrację Echo. Z kolei start-up Roxy postanowił zbudować własne oprogramowanie i sprzęt sterowane głosem, dla branży hotelarsko-gastronomicznej. Firma Synqq wprowadziła na początku roku aplikację do notatek, która wykorzystuje przetwarzanie głosu i języka naturalnego do dodawania notatek i wpisów kalendarza bez konieczności wstukiwania ich na klawiaturze.
Wszystkie te mniejsze przedsięwzięcia mają duże ambicje. Przede wszystkim nauczyły się jednak, że nie każdy użytkownik chce przekazywać swoje dane do Amazona, Google’a, Apple’a czy Microsoftu, czyli najważniejszych graczy w tworzeniu platform komunikacji głosowej.
Amerykanie chętnie kupują
W 2016 r. wyszukiwania głosowe stanowiły 20% wszystkich mobilnych wyszukiwań Google’a. Osoby, które korzystają na co dzień z tej technologii, wśród jej największych zalet wymieniają wygodę i multizadaniowość (np. opcję korzystania z wyszukiwarki podczas jazdy samochodem).
Analitycy z firmy Visiongain oceniają bieżącą wartość rynku inteligentnych cyfrowych asystentów na 1,138 mld dolarów. Tego typu mechanizmy stają się coraz bardziej powszechne. Według firmy Gartner, do końca 2018 r. już 30% naszych interakcji z technologią będzie odbywać się w drodze rozmów z systemami opartymi na głosie.
Brytyjska firma badawcza IHS Markit szacuje, że pod koniec tego roku rynek asystentów cyfrowych opartych na AI (sztucznej inteligencji) sięgnie 4 miliardów urządzeń, a liczba ta w 2020 r. może wzrosnąć do 7 miliardów.
Jak wynika z raportów eMarketer i VoiceLabs, w 2017 r. 35,6 miliona Amerykanów przynajmniej raz w miesiącu skorzystało z urządzenia aktywowanego głosem. To oznacza blisko 130-procentowy wzrost w porównaniu z rokiem poprzednim. Sam rynek cyfrowych asystentów ma zwiększyć się w 2018 r. o 23%. To oznacza, że korzystać z nich będzie już 60,5 miliona Amerykanów, co przełoży się na konkretne pieniądze dla ich producentów. RBC Capital Markets ocenia, że do roku 2020 interfejs Alexa przyniesie Amazonowi nawet 10 mld dolarów przychodów.
Upierz, upiecz, posprzątaj!
Interfejsy głosowe coraz odważniej wchodzą na rynek AGD i elektroniki użytkowej. Można to było dostrzec już podczas ubiegłorocznych targów IFA 2017. Amerykańskie przedsiębiorstwo Neato Robotics zaprezentowało np. robota próżniowego, który łączy się z jedną z kilku platform inteligentnego domu, w tym z amazonowym systemem Echo. Rozmawiając z inteligentnym głośnikiem Echo, można poinstruować maszynę, aby o określonej porze dnia i nocy sprzątała cały dom.
Na targach prezentowano też inne produkty sterowane głosem, począwszy od inteligentnych telewizorów sprzedawanych pod marką Toshiba przez turecką firmę Vestel, a skończywszy na podgrzewanych kocach niemieckiej firmy Beurer. Wiele z tych układów elektronicznych da się również aktywować zdalnie za pomocą smartfonów.
Zdaniem jednak przedstawicieli firmy Bosch, jest zbyt wcześnie, aby stwierdzić, która z opcji asystentów domowych stanie się dominująca. Niemiecka grupa technologiczna demonstrowała podczas IFA 2017 pralki (7), piekarniki i ekspresy do kawy, które łączą się z Echo. Bosch chciałby również, aby jego urządzenia były w przyszłości kompatybilne z platformami głosowymi Google’a i Apple’a.

Takie firmy jak Fujitsu, Sony i Panasonic rozwijają własne rozwiązania asystentów głosowych opartych na AI. Firma Sharp dodaje tę technologię do piekarników i małych robotów wprowadzanych na rynek. Grupa Nippon Telegraph & Telephone rekrutuje producentów urządzeń i zabawek w celu zaadaptowania systemu AI sterowanego głosem.
Koncepcja stara. Czy nadszedł wreszcie jej czas?
Tak naprawdę koncept głosowego interfejsu użytkownika (VUI) jest znany od dziesięcioleci. Każdy, kto wiele lat temu oglądał "Star Treka" lub "2001: Odyseję kosmiczną", spodziewał się zapewne, że około roku 2000 wszyscy będziemy kontrolować komputery za pomocą głosu. Zresztą nie tylko autorzy sci-fi dostrzegali potencjał tego typu interfejsów. W roku 1986 badacze Nielsena zapytali specjalistów z branży IT, jaka ich zdaniem zajdzie do roku 2000 największa zmiana dotycząca interfejsów użytkownika. Najczęściej wskazywali oni właśnie na rozwój interfejsów głosowych.
Nadzieje pokładane w tego typu rozwiązaniach mają swoją przyczynę. Komunikacja werbalna jest przecież najbardziej naturalnym sposobem świadomej wymiany myśli między ludźmi, więc wykorzystanie jej do interakcji "człowiek-maszyna" wydaje się być póki co najlepszym rozwiązaniem.
Jeden z pierwszych VUI, o nazwie Shoebox, został stworzony już na początku lat 60. XX wieku przez IBM. Był prekursorem dzisiejszych systemów rozpoznawania głosu. Rozwój urządzeń spod znaku VUI ograniczały jednak limity mocy obliczeniowej. Rozbijanie i interpretowanie mowy ludzkiej w czasie rzeczywistym wymaga dużej mocy, a dotarcie do punktu, w którym stało się to na dobre możliwe, zajęło ponad pięćdziesiąt lat.
Urządzenia z interfejsem głosowym zaczęły pojawiać się w masowej produkcji w połowie lat 90., ale popularności nie zdobyły. Pierwszym telefonem umożliwiającym obsługę głosową (wybieranie numeru) był Philips Spark, wypuszczony na rynek w 1996 r. Reklamowany jako przełomowe i proste w obsłudze urządzenie, nie był jednak wolny od ograniczeń technologicznych.
Kolejne telefony wyposażone w formy głosowego interfejsu (konstruowane przez firmy takie jak RIM, Samsung czy Motorola) pojawiały się na rynku regularnie, pozwalając użytkownikom na głosowe wybieranie numeru czy wysyłanie wiadomości tekstowych. Wszystkie one wymagały jednak pamiętania określonych poleceń i wymawiania ich w wymuszonej, sztucznej formie, dostosowanej do możliwości ówczesnych urządzeń. Generowało to dużą ilość błędów, co w efekcie prowadziło do niezadowolenia użytkowników.
Obecnie wkraczamy jednak w nową erę komputerów, w której postępy w uczeniu maszynowym i rozwoju sztucznej inteligencji stwarzają potencjał do rozmowy jako nowy sposób interakcji z technologią (8). Ważnym czynnikiem, mającym duży wpływ na rozwój VUI, stała się liczba urządzeń, obsługujących interakcję głosową. Obecnie prawie 1/3 światowej populacji posiada już smartfony, które mogą być wykorzystywane do tego rodzaju zachowań. Jak się zdaje, większość użytkowników jest też wreszcie gotowa zaadaptować interfejsy głosowe.

Zanim będziemy mogli jednak swobodnie porozmawiać z komputerem tak, jak robili to bohaterowie "Odysei kosmicznej", musimy pokonać szereg problemów. Maszyny ciągle nie najlepiej radzą sobie z niuansami językowymi. Poza tym wiele osób wciąż czuje się nieswojo, wydając polecenia głosowe wyszukiwarce.
Z danych statystycznych wynika, że głosowi asystenci są wykorzystywani przede wszystkim w domu lub w kręgu bliskich znajomych. Żaden z ankietowanych nie przyznał się do korzystania z wyszukiwarki głosowej w miejscach publicznych. Blokada ta najprawdopodobniej zniknie jednak wraz z upowszechnieniem się tej technologii.
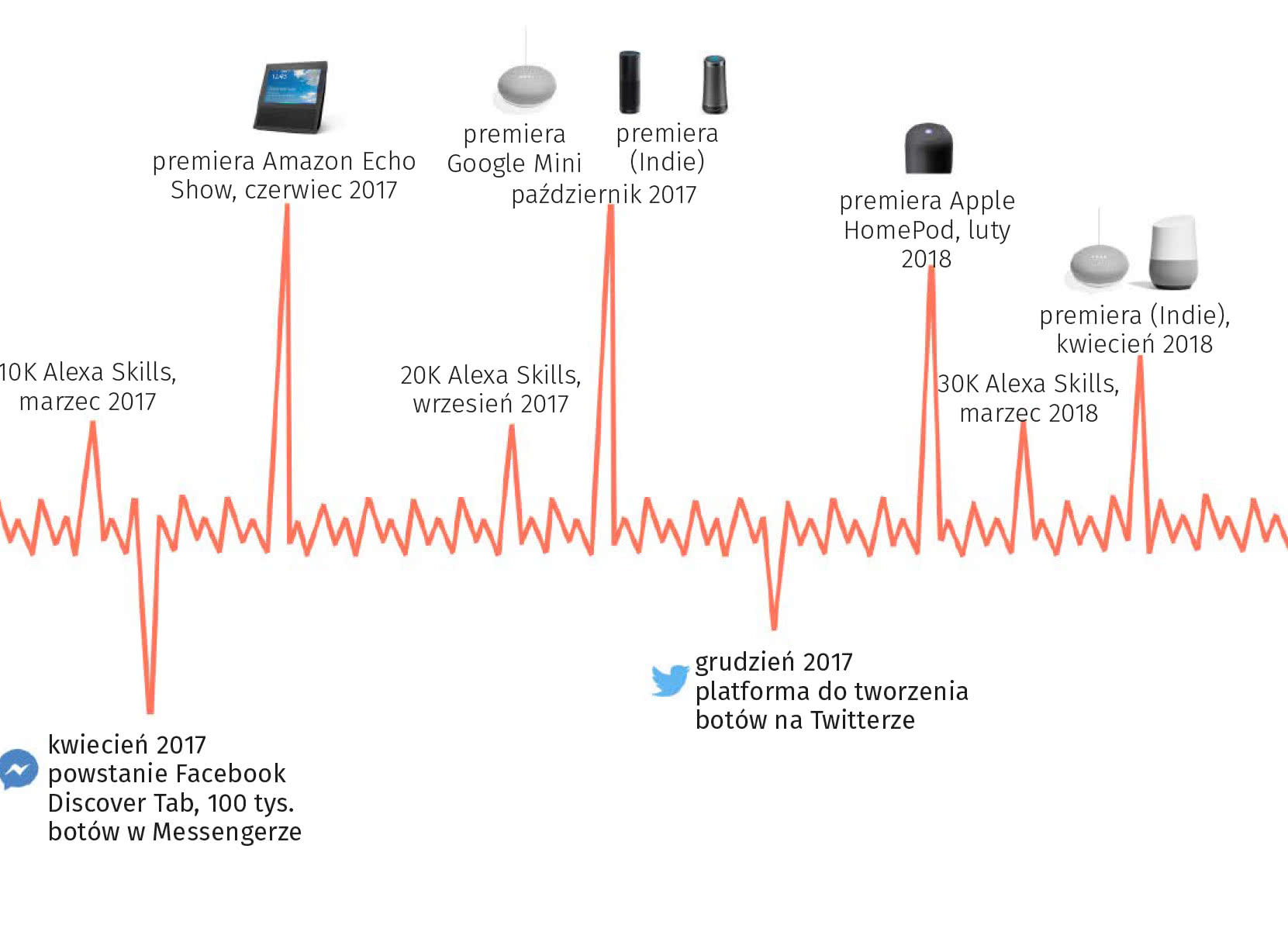
Kwestia technicznie trudna
Problemem, na jaki napotykają systemy Automatic Speech Recognition (ASR), jest wydobycie z sygnału mowy użytecznych danych i skojarzenie ich z konkretnym słowem, które dla człowieka ma określone znaczenie. Wypowiadane dźwięki za każdym razem są inne.
Zmienność sygnału mowy jest naturalną jego cechą, dzięki której np. rozpoznajemy akcent czy intonację. Każdy z elementów systemu rozpoznawania mowy ma określone zadanie. Na podstawie przetworzonego sygnału i jego parametrów powstaje model akustyczny, który jest kojarzony z modelem języka. System rozpoznawania może działać w oparciu o małą bądź dużą liczbę wzorców, co determinuje wielkość słownika, z jakim współpracuje. Mogą to być małe słowniki w przypadku systemów rozpoznających izolowane słowa bądź komendy, jak również duże bazy danych zawierające odpowiednik zbioru językowego oraz uwzględniające model językowy (gramatykę).
Wyzwania, z którymi zmagają się interfejsy głosowe, dotyczą przede wszystkim poprawnego zrozumienia mowy, w której np. często opuszczane są całe sekwencje gramatyczne, pojawiają się błędy językowe i fonetyczne, pomyłki, lapsusy, wady wymowy, homonimy, nieuzasadnione powtarzanie itd. Przy tym wszystkim systemy ASR muszą działać szybko i niezawodnie. Przynajmniej takie są oczekiwania.
Źródłem trudności są też sygnały akustyczne inne niż rozpoznawana mowa, dostające się na wejście systemu rozpoznającego, czyli wszelkiego rodzaju zakłócenia i szum. W najprostszym przypadku trzeba je odfiltrować. Zadanie to wydaje się rutynowe i łatwe - w końcu filtrowane są przeróżne sygnały i każdy elektronik wie, co należy w takiej sytuacji zrobić. Trzeba to jednak wykonać naprawdę dokładnie i starannie, jeśli wynik rozpoznawania mowy ma być zgodny z naszymi oczekiwaniami.
Stosowane współcześnie filtracje pozwalają usunąć zewnętrzne szumy pochwycone przez mikrofon wraz z sygnałem mowy oraz wewnętrzne właściwości samego sygnału mowy, utrudniające jego rozpoznanie. Znacznie trudniejszy problem techniczny pojawia się jednak w sytuacji, gdy zakłóceniem dla analizowanego właśnie sygnału mowy jest… inny sygnał mowy, czyli np. głośne dyskusje toczące się wokół. Zagadnienie takie znane jest w literaturze jako tzw. cocktail party problem. Wymaga już ono stosowania skomplikowanych metod tzw. dekonwolucji (odplątania) sygnału.
Na filtracji sygnału kłopoty z rozpoznawaniem mowy bynajmniej się nie kończą. Warto sobie uświadomić, że mowa niesie wiele różnego rodzaju informacji. Głos ludzki sugeruje płeć, wiek, rozmaite cechy osobnicze właściciela czy stan jego zdrowia. Istnieje obszerny dział inżynierii biomedycznej, który zajmuje się diagnostyką różnych chorób na podstawie charakterystycznych zjawisk akustycznych wykrywanych w sygnale mowy.
Są też zastosowania, w których głównym celem analizy akustycznej sygnału mowy staje się identyfikacja mówcy albo weryfikacja, czy jest on tym, za kogo się podaje (głos zamiast klucza, hasła albo PUK-kodu). Może mieć to znaczenie zwłaszcza dla technologii inteligentnych budynków.
Pierwszym elementem systemu rozpoznawania mowy jest mikrofon. Sygnał w takiej postaci, w jakiej rejestruje go mikrofon, pozostaje jednak generalnie mało przydatny. Badania wykazują, że kształt i przebieg fali dźwiękowej bardzo silnie zmieniają się w zależności od osoby, tempa mowy, częściowo także nastroju rozmówcy – natomiast w niewielkim stopniu odwzorowują samą treść wypowiadanych poleceń.
Sygnał trzeba więc odpowiednio przetworzyć. Współczesna akustyka, fonetyka i informatyka dostarczają łącznie bogaty zestaw narzędzi, które mogą być zastosowane do przetwarzania, analizy, rozpoznawania i rozumienia sygnału mowy. Wygodną podstawą są widma dynamiczne sygnału, tzw. spektrogramy dynamiczne. Daje się je dość łatwo uzyskać, a mowa reprezentowana w postaci spektrogramu dynamicznego może być w miarę łatwo rozpoznawana przy użyciu technik podobnych do tych, jakie są stosowane przy identyfikowaniu obrazów.
Proste elementy mowy (np. komendy) mogą być rozpoznawane na podstawie zwykłego podobieństwa całych spektrogramów. Przykładowo, słownik sterowanego głosem telefonu komórkowego zawiera zaledwie od kilkudziesięciu do kilkuset słów i zwrotów, z reguły z góry narzuconych, aby można je było łatwo i skutecznie identyfikować. Wystarcza to w prostych zadaniach sterowania, ale bardzo ogranicza ogólność zastosowań. Systemy budowane według schematu z reguły obsługują tylko konkretnych mówców, do których głosów są specjalnie trenowane. Jeśli więc pojawi się ktoś nowy, kto będzie chciał użyć swojego głosu do sterowania systemem, z dużym prawdopodobieństwem nie zostanie zaakceptowany.
Wynik tej operacji określany jest jako spektrogram 2-W, czyli widmo dwuwymiarowe. W bloku tym wpisana jest jeszcze jedna czynność, na którą warto zwrócić uwagę - segmentacja. Najogólniej mówiąc, chodzi o podzielenie ciągłego sygnału mowy na kawałki, podlegające oddzielnemu rozpoznawaniu. Dopiero z tych oddzielnych rozpoznań montuje się rozpoznanie całości. Takie postępowanie jest konieczne, bo długiej i złożonej wypowiedzi jednorazowo zidentyfikować się nie da. Na temat tego, jakie segmenty należy wyróżniać w sygnale mowy, napisano już całe tomy, więc nie będziemy w tym momencie przesądzać, czy wydzielonymi segmentami mają być fonemy (odpowiedniki głosek), sylaby czy może alofony.
Proces automatycznego rozpoznawania odwołuje się zawsze do jakichś cech obiektów. Dla sygnału mowy badano setki zestawów różnych parametrów Dysponując sygnałem mowy podzielonym na rozpoznawane ramki oraz mając wybrane cechy, za pomocą których ramki te są przedstawiane w procesie rozpoznawania, możemy przeprowadzić (dla każdej ramki osobno) klasyfikację, czyli przypisanie do ramki identyfikatora, który ją będzie dalej reprezentował.
Kolejną fazą jest montowanie ramek w pojedyncze słowa - najczęściej w oparciu o tzw. model niejawnych modeli Markowa (HMM - Hidden Markov Model). Następnie dochodzi do montowania ze słów kompletnych zdań.
W tym momencie możemy wrócić na chwilę do systemu Alexa. Na jego przykładzie widać, jak wieloetapowo przebiega proces maszynowego „zrozumienia” człowieka – dokładniej: wydawanego przez niego polecenia czy zadawanego pytania.
Zrozumienie słów, a zrozumienie znaczenia i pojęcie intencji użytkownika to zupełnie różne sprawy.
Dlatego kolejny etap stanowi działanie modułu NLP (Natural Language Processing), którego zadaniem jest rozpoznanie intencji użytkownika, czyli znaczenia wydanego polecenia/pytania w kontekście, w jakim ono zostało wypowiedziane. Jeżeli intencja zostaje zidentyfikowana, następuje przypisanie tzw. umiejętności, czyli konkretnej funkcji obsługiwanej przez inteligentnego asystenta. W przypadku pytania o pogodę wywoływane są źródła danych na temat pogody, które pozostaje przetworzyć na mowę (mechanizm TTS - text-to-speech). W efekcie użytkownik słyszy odpowiedź na zadane pytanie.
Głos? Grafika? A może jedno i drugie?
Większość znanych nowoczesnych systemów interakcji opiera się na pośredniku zwanym graficznym interfejsem użytkownika (GUI). Niestety, GUI nie jest najbardziej oczywistym sposobem interakcji z produktem cyfrowym. Wymaga bowiem od użytkowników, aby nauczyli się najpierw korzystać z interfejsu i przypominali sobie te informacje podczas każdej następnej interakcji. W wielu sytuacjach głos jest znacznie wygodniejszy, ponieważ interakcja z VUI wymaga po prostu rozmowy z urządzeniem. Interfejs, który nie zmusza użytkowników do nauki i przywoływania określonych poleceń lub metod interakcji, powoduje mniejsze problemy.
Ekspansja VUI nie oznacza oczywiście wyeliminowania bardziej tradycyjnych interfejsów - dostępne raczej będą interfejsy hybrydowe, łączące kilka sposobów interakcji.
Głosowy interfejs nie nadaje się do wykonywania wszystkich zadań w kontekście mobilnym. Za jego pomocą zadzwonimy do znajomego, prowadząc auto, a nawet wyślemy mu SMS-a, ale już sprawdzenie ostatnich przelewów może okazać się zbyt skomplikowane - ze względu na ilość informacji przekazywanych do systemu (user input) oraz generowanych przez system (system output). Jak sugeruje Rachel Hinman w książce "Mobile Frontier", stosowanie VUI staje się najbardziej wydajne podczas wykonywania zadań, w których ilość informacji na wejściu i wyjściu jest niewielka.
Połączony z Internetem smartfon to wygoda, ale jednocześnie uciążliwość (9). Za każdym razem, gdy użytkownik chce coś kupić lub skorzystać z nowej usługi, musi pobrać kolejną aplikację i założyć kolejne konto. Tworzy się tu pole do wykorzystania i rozwoju interfejsów głosowych. Zdaniem ekspertów, zamiast zmuszania użytkowników do instalacji wielu różnych aplikacji lub kreowania oddzielnych kont dla każdej usługi, VUI pozwoli przenieść ciężar tych uciążliwych zadań na asystenta głosowego wyposażonego w sztuczną inteligencję. To on w wygodny sposób będzie wykonywał uciążliwe czynności. My będziemy mu jedynie wydawać polecenia.

W dzisiejszych czasach nie tylko telefon i komputer są podłączone do Internetu. Inteligentne termostaty, światła, czajniki i wiele innych urządzeń zintegrowanych z Internetem Rzeczy również ma połączenie z siecią (10). Mamy więc wokół siebie bezprzewodowo połączone urządzenia, które wypełniają nasze życie, ale nie wszystkie z nich naturalnie pasują do graficznego interfejsu użytkownika. Korzystanie z VUI pomoże je łatwo wkomponować w nasze środowisko.

Tworzenie interfejsu użytkownika głosowego wkrótce stanie się kluczową umiejętnością projektantów. Oto prawdziwe wyzwanie - konieczność wdrażania systemów opartych na głosie zachęci do skupienia się w większym stopniu na projektowaniu antycypacyjnym, czyli dążeniu do zrozumienia początkowych intencji użytkownika, przewidywaniu na każdym etapie rozmowy jego potrzeb i oczekiwań.
Głos jest efektywnym sposobem wprowadzania danych - pozwala użytkownikom na szybkie wydawanie poleceń do systemu na ich własnych warunkach. Z kolei ekran zapewnia efektywny sposób wyświetlania informacji: umożliwia systemom jednoczesne wyświetlanie dużej ilości informacji, zmniejszając obciążenie pamięci użytkowników. Logicznie rzecz biorąc, połączenie ich w jeden system brzmi zachęcająco.
Inteligentne głośniki, takie jak Echo Amazon i Google Home, nie oferują w ogóle wyświetlacza wizualnego. Dzięki znacznej poprawie dokładności rozpoznawania głosu na umiarkowanych odległościach umożliwiają obsługę w trybie głośno mówiącym, co z kolei zwiększa ich elastyczność i wydajność - są pożądane nawet dla użytkowników mających już smartfony z obsługą głosową. Jednak brak ekranu jest ogromnym ograniczeniem.
Do informowania użytkowników o możliwych poleceniach mogą być wykorzystywane tylko sygnały dźwiękowe, a głośne odczytywanie danych wyjściowych staje się nużące, z wyjątkiem najprostszych zadań. Ustawianie timera poleceniem głosowym podczas gotowania jest świetne, ale zmuszanie do zadawania pytań, ile czasu zostało do końca, już niekoniecznie. Uzyskanie zwykłej prognozy pogody staje się testem pamięci dla użytkownika, który przez cały tydzień musi słuchać i wchłaniać serię faktów, zamiast zbierać je z ekranu na pierwszy rzut oka.
Projektanci zaprojektowali już rozwiązanie hybrydowe, Echo Show (11), w którym do podstawowego inteligentnego głośnika Echo dodano ekran wyświetlacza. Znacznie rozszerza to funkcjonalność sprzętu. Echo Show jest jednak wciąż znacznie mniej zdolne do wykonywania podstawowych funkcji, które od dawna są dostępne na smartfonach i tabletach. Nie może (jeszcze) np. przeglądać stron internetowych, pokazywać recenzji lub wyświetlać zawartości koszyka zakupów Amazona.

Wyświetlacz wizualny jest z natury bardziej efektywnym sposobem udostępniania ludziom dużej ilości informacji niż tylko dźwięk. Projektowanie voice-first może znacznie poprawić interakcję głosową, ale w dłuższej perspektywie arbitralne niestosowanie wizualnego menu dla dobra interakcji voice-first byłoby jak walka z jedną ręką związaną za plecami. Z uwagi na zbliżającą się złożoność całościowych, inteligentnych interfejsów głosowych i ekranowych, projektanci powinni więc poważnie brać pod uwagę hybrydowe podejście do interfejsów.
• militaria (polecenia głosowe w samolotach czy helikopterach, np. F16 VISTA),
• automatyczna transkrypcja tekstu (Speech to text),
• interaktywne systemy informacyjne (Prime - Speech, portale głosowe),
• urządzenia mobilne (telefony, smartfony, tablety),
• robotyka (Cleverbot - systemy ASR w połączeniu ze sztuczną inteligencją),
• motoryzacja (sterowanie podzespołami auta bez użycia rąk, np. Blue&Me),
• aplikacje domowe (systemy typu "inteligentny dom").
Uwaga na bezpieczeństwo!
Samochody, urządzenia, systemy ogrzewania/chłodzenia oraz bezpieczeństwa domowego, a także niezliczona liczba urządzeń - wszystko to zaczyna wykorzystywać interfejsy głosowe, często zasilane przez AI. Na obecnym etapie dane pozyskiwane z milionów konwersacji z maszynami trafiają do chmur obliczeniowych. Dość oczywiste jest, że interesują się nimi specjaliści od marketingu. I nie tylko oni.
Niedawny raport ekspertów ds. bezpieczeństwa firmy Symantec zaleca, aby użytkownicy poleceń głosowych nie zarządzali funkcjami bezpieczeństwa, takimi jak zamki w drzwiach, ani tym bardziej systemami ochrony domów. To samo dotyczy przechowywania haseł lub poufnych informacji. Bezpieczeństwo sztucznej inteligencji i inteligentnych produktów nie zostało jeszcze dobrze zbadane.
Gdy urządzenia w całym domu słuchają każdego słowa, ryzyko włamania się i niewłaściwego użycia systemu staje się niezwykle ważną kwestią. Jeśli osoba ze złymi intencjami uzyska dostęp do sieci lokalnej lub powiązanych adresów e-mail, ustawienia inteligentnego urządzenia mogą zostać zmienione lub przywrócone do stanu fabrycznego, co spowoduje utratę cennych informacji i usunięcie historii użytkownika.
Inaczej rzecz ujmując - specjaliści od bezpieczeństwa obawiają się, że zarządzana głosem i VUI sztuczna inteligencja nie jest jeszcze dostatecznie inteligentna, aby obronić nas przez potencjalnymi zagrożeniami i utrzymać język za zębami, gdy zapyta ją o coś ktoś obcy.
Mirosław Usidus