
 Arcymistrz Hikaru Nakamura – mistrz świata w szachach 960
| Szachy
Arcymistrz Hikaru Nakamura – mistrz świata w szachach 960
| Szachy
Hikaru Nakamura jest cudownym szachowym dzieckiem, streamerem, youtuberem, pięciokrotnym mistrzem USA w szachach i aktualnym mistrzem świata w szachach losowych Fischera. Stany Zjednoczone ...
0
0
 Czy człowiek postawi kiedyś stopę na Marsie? Sąsiedzi Ziemi - część 1
| Fizyka
Czy człowiek postawi kiedyś stopę na Marsie? Sąsiedzi Ziemi - część 1
| Fizyka
Dwie najmniej odległe od Ziemi planety to Wenus i Mars. Jakkolwiek do Wenus mamy bliżej niż do Marsa, to panują tam ekstremalne warunki, w których człowiek nie byłby w stanie przeżyć ...
0
0
 Wektorki
| Matematyka
Wektorki
| Matematyka
Ten odcinek „Rozmaitości matematycznych” powstał po zajęciach ze studentami Wyższej Szkoły Informatyki Stosowanej i Zarządzania. Uczę tam od 25 lat, ale każdego roku trochę inaczej. ...
0
0
 Metal numer 2 z rodziną - część 3
| Chemia
Metal numer 2 z rodziną - część 3
| Chemia
Glin to najbardziej rozpowszechniony i najważniejszy pierwiastek z grupy 13. Co do tego nie ma wątpliwości, ale i pozostali członkowie rodziny warci są wzmianki. Jeden z nich ma ...
0
0
 Inżynieria wzornictwa przemysłowego
| MT studiuje
Inżynieria wzornictwa przemysłowego
| MT studiuje
Nie każdy z nas analizuje, dlaczego niektóre przedmioty codziennego użytku są nie tylko funkcjonalne, ale i przyjemne dla oka. Przyjmujemy to za coś oczywistego, intuicyjnie wybierając ...
0
0
 Sama chemia
| Chemia
Sama chemia
| Chemia
Pozostańmy jeszcze przy tematyce noblowskiej z ubiegłego roku, tym razem w wersji humorystycznej. Ostatni IgNobel z dziedziny chemii został przyznany za pomysł dodawania tworzywa sztucznego ...
0
0
 Warunki równowagi ciał
| Fizyka
Warunki równowagi ciał
| Fizyka
Z pojęciem siły spotykamy się na lekcjach fizyki już od szkoły podstawowej. Jest to wielkość, która opisuje wzajemne oddziaływanie ciał. Co istotne, jest to wielkość wektorowa, zatem ...
0
0
 Zarządzanie i inżynieria produkcji
| MT studiuje
Zarządzanie i inżynieria produkcji
| MT studiuje
W 1913 roku Henry Ford uruchomił pierwszą linię montażową samochodów. Jeden Model T schodził z taśmy co 93 minuty. Wcześniej budowa jednego auta zajmowała 12 godzin. To była rewolucja. ...
0
0
 Metawersum. Jak zgasł wirtualny entuzjazm
| Koniec i co dalej
Metawersum. Jak zgasł wirtualny entuzjazm
| Koniec i co dalej
Pod koniec 2025 roku firma Meta, do której należy m.in. Facebook i Instagram, ogłosiła zamiar znacznego ograniczenia budżetu Reality Labs budującego od kilku lat coś, co nazwano „metawersum”. ...
0
0
 Paliwa kopalne
| Odkryj historię wynalazków
Paliwa kopalne
| Odkryj historię wynalazków
Historia paliw to opowieść o rozwoju cywilizacji – od starożytnych lamp naftowych i węgla wykorzystywanego przez Rzymian, po rewolucję przemysłową i współczesne dążenia do odejścia ...
0
0
 Legendarny sędzia szachowy Andrzej Filipowicz
| Szachy
Legendarny sędzia szachowy Andrzej Filipowicz
| Szachy
Doktor nauk technicznych Andrzej Filipowicz jest jednym z najwybitniejszych sędziów szachowych na świecie. Należał do grupy czołowych polskich szachistów, od 1975 roku mistrz międzynarodowy, od ...
0
0
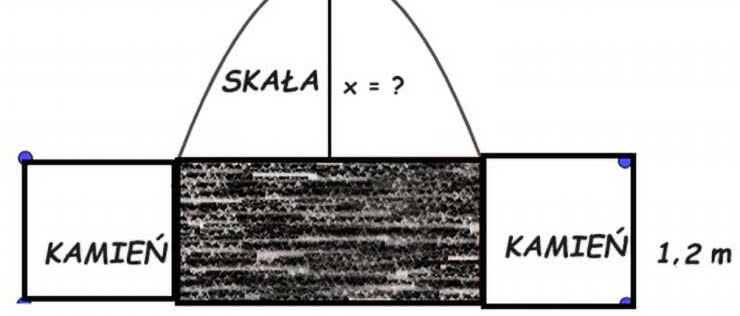 Buraki, kurniki w ZSRR i rynny potrząsalne
| Matematyka
Buraki, kurniki w ZSRR i rynny potrząsalne
| Matematyka
Przy okazji kolejnych porządków na półkach z książkami zajrzałem znów do starych zbiorów zadań i po raz kolejny doznałem mieszanych wrażeń: coś między zdumieniem, podziwem i niechęcią. ...
0
0


