Grozi nam potop danych i energetyczna apokalipsa, ale pecety trwają. Komputery - co dalej?

Jakie są główne kierunki owych właśnie zachodzących zmian w świecie komputerów? Poza dążeniem do uzyskania większej mocy obliczeniowej coraz powszechniejsza jest adaptacja technik uczenia maszynowego a także rozwiązań IoT. Każdy z tych nurtów przenikają dążenia do redukcji zużycia energii związanej z obliczeniami, szczególnie w centrach danych.
W świetle raportu Stowarzyszenia Przemysłu Półprzewodnikowego (SIA) z 2016 roku prognozującego, że do 2040 roku komputery na świecie będą zużywać więcej energii elektrycznej niż wszystkie kraje łącznie będą w stanie wyprodukować, zmiany zmierzające do ograniczenia energochłonności mają kluczowe znaczenie.
Panuje przekonanie, że nowe procesory obliczeniowe, oparte na dotychczasowej konstrukcji, nie zwiększają już ogólnej wydajności, głównie ze względu na fundamentalne ograniczenia stale kurczących się tranzystorów krzemowych. Prawo Moore’a w klasycznej postaci rzeczywiście przestało obowiązywać. Trwają poszukiwania alternatyw dla krzemu lub innego podejścia, jeśli to wciąż ma być krzem. Wszystko, ma się rozumieć, z myślą nie tylko o szybkości i wydajności, ale też o użyciu energii.
Nanorurki, magnetyzm i światło
Są pewne komputerowo-elektroniczne innowacje a raczej kierunki innowacji, o których mówimy i piszemy od lat, ale jakoś wciąż nie możemy doczekać się praktycznych wdrożeń. Należy do nich np. pomysł integracji nanorurek węglowych z układami scalonymi, który wciąż ma status rozwiązania obiecującego, ale niezrealizowanego w praktyce, choć niektóre ośrodki i firmy, choćby Aligned Carbon, zapewniają, że już wkrótce da nam to niezrównaną wydajność w chipach nowego typu. Zobaczymy.
Skoku wydajności oczekuje się również od zastosowania w układach pamięci typu MRAM (Magnetic Random Access Memory), ultraszybkiego nośnika o dużej gęstości. Głównym ograniczeniem w skalowaniu tego rozwiązania jest obecność zanieczyszczeń strukturalnych w materiałach magnetycznych, co zmniejsza pojemność. Rozwiązać mogłaby to technika nazywana spin-Ion, w której wykorzystuje się napromieniowanie materiałów magnetycznych wiązką lekkich jonów. Rozwiązania te mają być stosowane na początek tylko w superkomputerach, ale z czasem staną się prawdopodobnie integralną częścią wielu innych platform obliczeniowych (2).

Za jedną z barier współczesnych układów przetwarzania danych w aplikacjach uważa się zbyt małą szybkość komunikacji pomiędzy pamięcią a układami przetwarzającymi. Aby wesprzeć takie zastosowania, jak uczenie maszynowe i nowe typy generowanej komputerowo rzeczywistości (AR/VR), firmy MemComputing i UpMEM proponują zintegrowanie procesorów obliczeniowych w pamięci. Skraca to czas obliczeń, jednocześnie zmniejszając ilość potrzebnej pamięci i zużycie energii.
Odpowiedź na problemy energetyczne współczesnych komputerów, a przede wszystkim wielkich ich kompleksów zgromadzonych w centrach obliczeniowych, być może znajdziemy w świetle. Optoelektronika pozwala na wykonywanie obliczeń z większą prędkością przy znacznie mniejszym zużyciu energii, zapewniając tym samym wyższą wydajność na jednostkę mocy. Ponieważ tradycyjnie procesory optoelektroniczne wymagają znacznie więcej przestrzeni fizycznej, nie są one powszechnie stosowane.
Jednak dla centrów danych oszczędność energii jest ważniejsza niż zajmowana przestrzeń, dzięki czemu procesory optoelektroniczne mogą stać się tam wkrótce dominującą platformą sprzętową. Czynnikiem ograniczającym chipy optoelektroniczne jest techniczna trudność w umieszczaniu wystarczającej liczby laserów na chipie w celu osiągnięcia wysokiej wydajności przy niskiej mocy. Rozwiązaniem może być technika Iris Light Technologies, pozwalająca na drukowanie setek laserów bezpośrednio na chipach przy użyciu nanotechnologicznego "tuszu".
Na krawędzi
Specyficzne wymagania techniczne ma upowszechniający się model obliczeniowy Edge Computing, którego podstawowym założeniem jest fizyczne przybliżenie obliczeń i przechowywania danych do ich źródła, czyli do urządzeń, w których dane są generowane. Zmniejsza to opóźnienia i zwiększa autonomię urządzeń brzegowych, którymi mogą być np. współpracujące w rojach roboty lub autonomiczne drony, natychmiastowo przetwarzające informacje, aby móc sprawnie i bezpiecznie działać.
Przesyłanie informacji do chmury do przeanalizowania, a następnie zwracanie ich do urządzenia brzegowego zajmuje zbyt dużo czasu, aby zagwarantować odpowiednie i wystarczająco szybkie reakcje (3). Poza tym wzrasta przez to zapotrzebowanie na zasoby obliczeniowe i pamięci masowe.
Szczególnie w przypadku aplikacji, od których wymaga się szybkiego działania i reagowania, rośnie potrzeba podejmowania decyzji bez wysyłania danych do chmury. Oznacza to jednak, że urządzenia brzegowe muszą sprostać w sensie energetycznym. Dlatego firmy takie jak Synthara pracują nad nowego typu układami przetwarzającymi, które umożliwiają aplikacjom opartym na sztucznej inteligencji działanie przy bardzo niskim zużyciu energii, w celu dostosowania się do ograniczonej wydajności baterii zasilających urządzenia IoT.
Przetwarzanie zostaje przeniesione na krawędź (ang. "Edge" – stąd nazwa Edge Computing), czyli tam, gdzie rodzą się dane. Przykładem "krawędziowej" techniki komputerowej są auta firmy Tesla. Ogromna większość danych tworzonych przez samochód Tesli nigdy nie trafia do chmury. Nie są one nawet przechowywane. Tesla zapisuje niewielką część danych. Niektóre z nich od czasu do czasu podłączane są do chmury, aby trenować modele sztucznej inteligencji.
Problem danych, a zwłaszcza ich ilości w relacji do mocy obliczeniowej (4) jest jednym z głównych bólów głowy współczesnej informatyki. Rujia Wang i Kyle Hale oraz Xian-He Sun, wybitni specjaliści w dziedzinie informatyki z Illinois Institute of Technology, prowadzą na zlecenie amerykańskiej National Science Foundation prace nad nową architekturą komputerową, która ma radykalnie zredukować energię i czas, potrzebne do przetwarzania dużych zbiorów danych.
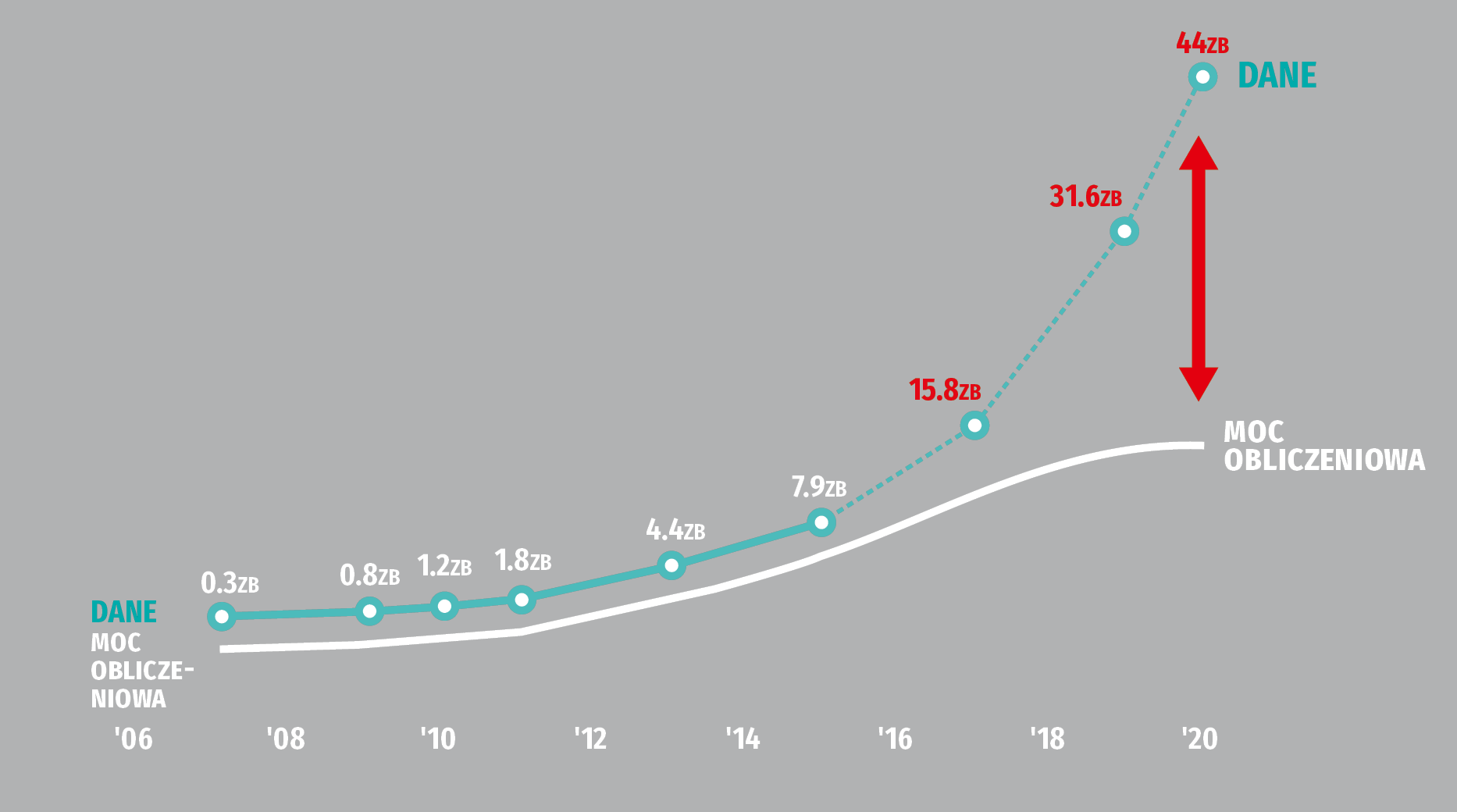
"W systemach komputerowych, z których obecnie korzystamy, mamy CPU (centralną jednostkę obliczeniową) i pamięć do przechowywania danych", wyjaśnia Wang w opublikowanym komunikacie. "Gdy chcemy przetwarzać informacje, dane te muszą być przeniesione z pamięci do procesora, co nie jest problemem, gdy nie mamy dużej ilości danych. Ale jeśli chodzi o zadania z zakresu uczenia maszynowego, eksploracji danych lub specyficzne wyzwania, jak np. sekwencjonowanie genomu, to ruch danych jest bardzo duży. Pojawiają się wąskie gardła z powodu ograniczonej przestrzeni i oczywiście skokowo rośnie zużycie energii".
Propozycja Wanga i zespołu z Illinois Tech polega na rozpoczęciu wstępnego przetwarzania danych już w pamięci przed przeniesieniem ich do procesora, co powinno zmniejszyć ilość danych, które muszą migrować do CPU i sprawi, że przetwarzanie w CPU będzie bardziej wydajne. Brzmi jak proste rozwiązanie, ale w rzeczywistości wymaga to dość złożonego połączenia wielu różnych nowych technik zarówno po stronie sprzętu, jak i oprogramowania.
Pogłoski o śmierci peceta mocno przesadzone
W ciągu ostatnich kilkunastu lat niejednokrotnie mogliśmy usłyszeć i przeczytać o tzw. erze postpecetowej. Pojęcie to powstało pod wpływem zmian obserwowanych w późnych latach 2000 i później, w ubiegłej dekadzie. Chodzi przede wszystkim o obserwowany przez lata spadek sprzedaży komputerów osobistych (PC) na rzecz urządzeń mobilnych, smartfonów i tabletów, a także innych komputerów przenośnych, sprzętu noszonego itp.
Pierwszy prognozę "końca pecetów" sformułował badacz z MIT, David D. Clark w 1999 roku, który widział przyszłość komputerów jako "nieuchronnie heterogeniczną" w "sieci wypełnionej usługami". Clark, jako jeden z pierwszych, opisywał świat, w którym "wszystko" będzie łączyć się z Internetem, obliczenia będą wykonywane głównie przez urządzenia informatyczne, a dane będą przechowywane przez scentralizowane usługi hostingowe zamiast na fizycznych dyskach
Bill Gates, wówczas szef Microsoftu i Steve Jobs, szef Apple, również w tamtym czasie przewidywali przesunięcie w kierunku urządzeń mobilnych. Jobs spopularyzował termin "post-PC" w 2007 roku podczas premiery pierwszego iPhone’a, a w 2011 roku uruchomił iCloud, usługę umożliwiającą linii produktów Apple synchronizację danych z komputerami PC za pośrednictwem usług w chmurze, uwalniając urządzenia iOS od zależności od komputera PC.
Podczas prezentacji w styczniu 2012 roku, wiceprezes Intela Tom Kilroy zakwestionował nadejście ery post-PC, powołując się na badanie studentów college’u, w którym 66% respondentów nadal uważało komputer osobisty za "najważniejsze urządzenie w ich codziennym życiu".
Wkrótce także media zaczęły kwestionować nadejście ery post-PC. Najczęściej powtarzania opinia głosiła, że te podziały i klasyfikacje mają już niewielki sens w sytuacji, gdy urządzenia przenośne, choćby smartfony, są w zasadzie komputerami, w dodatku o mocy i możliwościach większych niż "definicyjne" pecety sprzed dwu dekad. Poza tym nie słabła popularność nie tylko laptopów, ale nawet ciężkich komputerów stacjonarnych w niektórych zastosowaniach, np. w grach.
W dodatku właśnie ostatnio widzimy ponowny wzrost sprzedaży tych pecetów, co to "miały odejść". Różne raporty rynkowe mówią o kilkunastoprocentowym wzroście w 2020 roku w porównaniu z rokiem poprzednim. Oczywiste czynniki napędzające ten wzrost mają związek z pandemicznymi warunkami, pracą w domu i potrzebami zdalnego nauczania. Jednak eksperci uważają, że nie tylko o to chodzi, i pecety, laptopy, notebooki, czy jakieś inne produkty w jeszcze niesprecyzowanej postaci, ale o podobnym kształcie i charakterze, pozostaną z nami, bo są po prostu wygodnym narzędziem.
Mirosław Usidus