Uzyskać więcej mniejszym kosztem

Zespoły badawcze w ośrodkach akademickich i przemyśle prywatnym intensywnie pracują nad sposobami uczynienia sztucznej inteligencji mniej wymagającą pod względem ilości danych. Pojawiły się nowe metody szkolenia, takie jak uczenie jednostrzałowe (one-shot learning) i uczenie mniej niż jednostrzałowe (less-than-one-shot learning), a także niezliczone wysiłki zmierzające do upodobnienia sztucznej inteligencji do ludzkiego mózgu, który działa pod względem ekonomii i zużycia energii o wiele lepiej niż najsprawniejsze znane nam sztuczne sieci neuronowe.
Optymistyczne prognozy uspokajają martwiących się o pracę
Coraz więcej firm na rynku stawia na rozwiązania oparte na sztucznej inteligencji (AI) - wynika z opublikowanych w styczniu 2021 r. analiz firmy Capgemini. Około 85 proc. przedsiębiorstw testowało lub wykorzystywało AI. Jak wynika z danych, ponad połowa firm oferujących usługi finansowe prowadzi prawie 40 proc. interakcji z klientem przy wykorzystaniu AI, zaś 54 proc. kupujących każdego dnia wchodzi w interakcje z algorytmami sztucznej inteligencji m.in. przez wirtualnych agentów, skanery biometryczne, interaktywne przymierzalnie, czy personalizowane oferty. Nadal kluczowymi obszarami są marketing i sprzedaż, gdzie firmy w poszukiwaniu nowych możliwości i sposobów pozyskiwania klientów sięgają po innowacyjne rozwiązania.
Inny, opublikowany mniej więcej w tym samym czasie raport firmy PwC, pt. "What’s the real value of AI for your business and how can you capitalise?" głosi, iż sztuczna inteligencja przyczyni się do wzrostu globalnego PKB o 14 proc., a więc o 15,7 biliona dolarów do 2030 r. Stać się tak ma dzięki oferowanej przez AI automatyzację, procesów biznesowych (autonomiczny transport i roboty), wspomożenie pracowników przez AI, wzrost popytu dzięki nowym produktom o lepszej jakości. Jak sądzą analitycy PwC w pierwszym okresie wzrost wynikać będzie ze zwiększania się produktywności, automatyzacji, doskonalenia procesów. Im bliżej do 2030 r., tym istotniejsze okażą się korzyści wynikające z poprawy jakości produktów i ich personalizacji. Jednak nie wszyscy skorzystają tak samo. Zdaniem autorów raportu PwC, na rozwoju AI zyskają szczególnie Chiny (wzrost PKB o 26,1 proc.) i Ameryka Północna (wzrost PKB o 14,5 proc.). Spore korzyści odniosą także rozwinięte kraje Azji i Europy. Mniej zyskają natomiast kraje rozwijające się.
A co z ekonomią zwykłych ludzi, którzy chcą w tych przemianach zachować pracę, czyli dochody? Według analiz, na największe ryzyko utraty pracy wskutek automatyzacji są narażeni pracownicy wprowadzający dane, agenci przewozowi, zegarmistrze czy telemarketerzy. Bezpiecznie czuć się mogą natomiast m.in. terapeuci, psychologowie, dentyści i naukowcy medyczni. Raporty zwykle uspokajają, zwracając uwagę na nowe szanse zawodowe, gdyż znajomość sztucznej inteligencji ma stać się po prostu kolejną umiejętnością wymaganą od "ludzkich" pracowników. Ludmiła Aleksiejewa, José Azar, Mireia Gine, Sampsa Samila i Bledi Taska w analizie, która ukazała się w serwisie Voxeu.org, zauważają, że osoby, które opanują związane ze sztuczną inteligencją umiejętności, mogą liczyć na średnio o 11 proc. wyższe pensje niż ich koledzy na podobnych stanowiskach, gdzie znajomość AI nie jest wymagana. Zapotrzebowanie na umiejętności związane ze sztuczną inteligencją mierzone liczbą ofert pracy wzrosło w latach 2010-19 w USA dziesięciokrotnie w liczbach absolutnych oraz czterokrotnie szybciej niż w przypadku innych ofert pracy.
Okazuje się, nawiasem mówiąc, że powstają algorytmy, które mogą usprawniać ekonomię na wyższym poziomie niż algorytmy automatyzujące w fabrykach i biurach. Stworzony przez firmę Salesforce AI Economist uczy się dynamicznej polityki podatkowej, która godzi postulat sprawiedliwego obciążenia daninami z wydajnością dochodową dla budżetu państwa, przewyższając w przeprowadzanych symulacjach znane systemy podatkowe. To pierwsze narzędzie, w którym stosuje się techniki wzmocnionego uczenia maszynowego w polityce fiskalnej.
Eksperymenty sugerują, że AI Economist może poprawić równowagę pomiędzy sprawiedliwością systemu a wydajnością o 16 proc. w porównaniu z uznanym za dużo lepszy, niż obowiązujący obecnie w USA, modelem podatkowym zaproponowanym przez Emmanuela Saeza z Uniwersytetu Kalifornijskiego w Berkeley. Jednak symulacje makroekonomiczne oparte na sztucznej inteligencji nadal są pełne ograniczeń. Nie modelują one jeszcze dobrze czynników ludzkich zachowań i interakcji międzyludzkich, w tym także uwarunkowań społecznych, opierając się na modelu stosunkowo niewielkiej gospodarki.
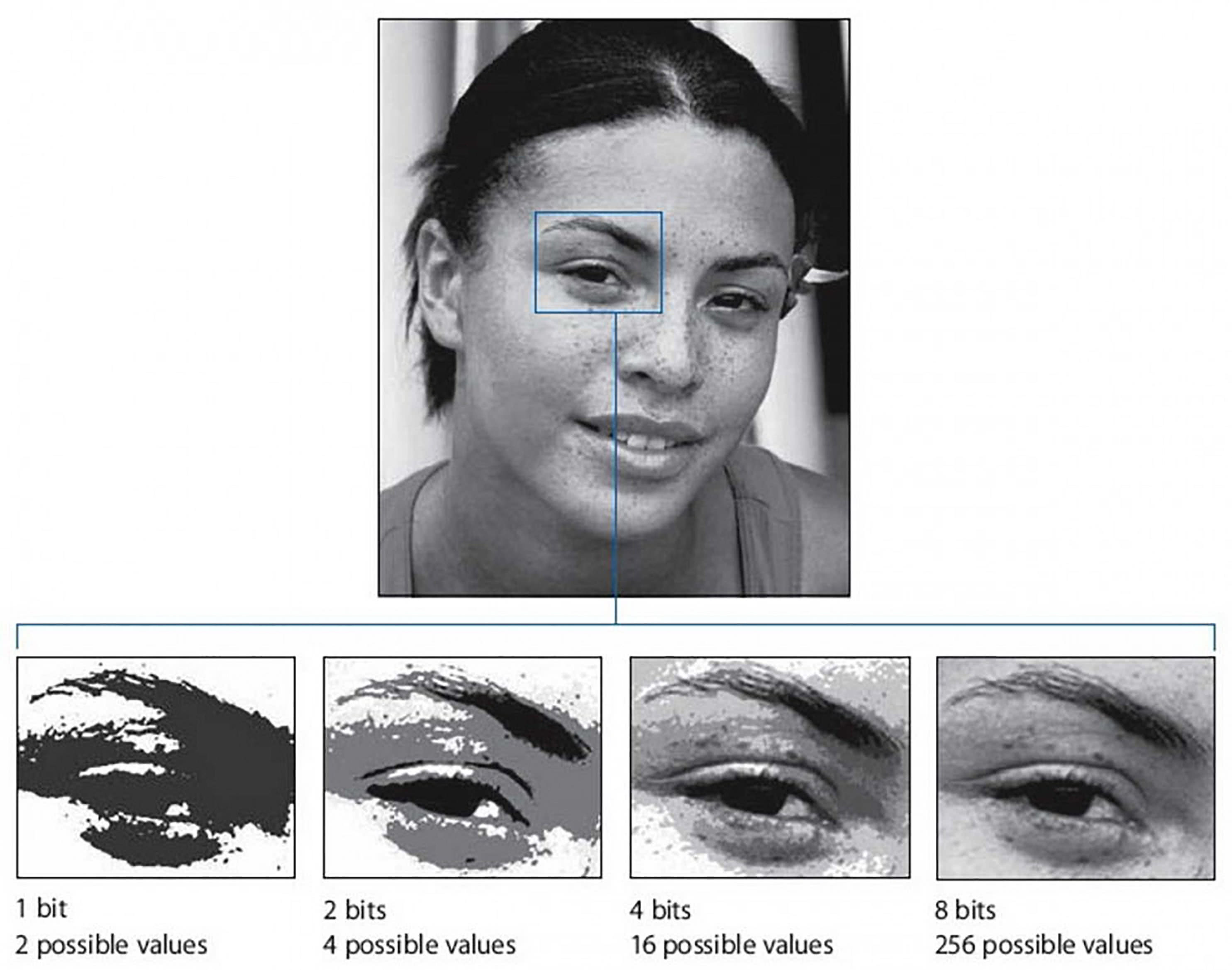
Jak zmieścić dane z szesnastu bitów w czterech bitach
Pomimo tych optymistycznych prognoz i przewidywań, niektóre formy AI mają wciąż poważny problem z ekonomią własnego działania. Na przykład głęboka nauka jest głęboko, nomen omen, nieefektywna energetycznie. Wymaga ogromnych ilości danych i obfitych zasobów obliczeniowych, co powoduje erupcję zużycia energii elektrycznej. W ciągu ostatnich kilku lat ten problem wskutek wzrostu liczby projektów tylko się pogłębił. Modele o gargantuicznych rozmiarach, szkolone na miliardach punktów danych przez wiele dni, są w modzie i prawdopodobnie nie przestaną być.
Niedawno badacze IBM zaproponowali inny model nauki maszynowej. Ich pomysł zmniejszyłby liczbę bitów, potrzebnych do reprezentowania danych, z szesnastu bitów, które są obecnie standardem branżowym, do zaledwie czterech. Wdrożenie tej techniki mogłoby zwiększyć szybkość uczenia maszynowego i ponad siedmiokrotnie obniżyć koszty zużywanej energii. Mogłoby to również potencjalnie umożliwić szkolenie zaawansowanych modeli AI na takich urządzeniach jak smartfony i podobny mały sprzęt. Dzięki temu proces ten byłby też bardziej dostępny dla badaczy spoza dużych, bogatych w zasoby przedsiębiorstw technologicznych.
Chodzi o to, aby skalę szesnastobitową niejako skompresować do czterobitowej, co oczywiście normalnie wiąże się z utratą precyzji danych (2). Trik wymyślony w 2018 roku przez IBM polega na zmienianiu skali aktywacji i wag w sieci neuronowej dla każdej rundy treningu, aby uniknąć znaczących strat precyzji. Jak przedstawić w czterech bitach wartości pośrednie, które pojawiają się podczas treningu? Wyzwaniem jest to, że wartości te mogą rozciągać się na znacznie większej skali, mogą one być małe, np. 0,001, lub wielkie, choćby 1000. Próba liniowego skalowania tego do wartości nawet szesnastu bitów powoduje utratę rozdzielczości, a co dopiero czterobitowa reprezentacja. Jednak znaleziono rozwiązanie - było to zastosowanie skali logarytmicznej do wartości pośrednich.
Zanim jednak ekonomiczne głębokie uczenie maszynowe stanie się praktyką potrzeba jeszcze sporo prac na tą nową techniką. Zespół z IBM na razie jedynie symulował wyniki tego rodzaju szkolenia. Wykonanie tego w rzeczywistym świecie wymagałoby nowego czterobitowego sprzętu. Zdaniem Kailasha Gopalakrishnana, naukowca z IBM, który prowadził ten projekt, na czterobitowy sprzęt do deep learningu trzeba będzie czekać jeszcze kilka lat.
Destylowanie danych
Aby uzyskać model AI rozpoznający konia, musisz pokazać mu tysiące obrazów koni. Dlatego technologia ta jest kosztowna obliczeniowo i bardzo różni się od sposobu uczenia się ludzi. Dziecku zazwyczaj wystarczy pokazać kilka przykładów, lub nawet tylko jeden, by umiało go potem rozpoznać przez całe życie. Dzieci czasem wręcz nie potrzebują żadnych przykładów, aby coś umieć zidentyfikować. Po pokazaniu zdjęcia konia i nosorożca i przekazie, że jednorożec jest czymś pośrednim, mogą rozpoznać mityczne stworzenie w książce z obrazkami za pierwszym razem.

Naukowcy Uniwersytetu Waterloo w kanadyjskim Ontario uważają, że AI również powinna umieć tak jak ludzkie dzieci. Nazywają tę koncepcję hiper ekonomicznego uczenia maszynowego - LO-shot. Sprowadza się to do dążenia, żeby model AI był w stanie trafnie rozpoznać więcej obiektów niż liczba przykładów, na których został przeszkolony. Badacze po raz pierwszy zademonstrowali ten pomysł podczas eksperymentowania z popularnym wizualnym zestawem danych, znanym jako MNIST. MNIST, który zawiera 60 tys. obrazów szkoleniowych ręcznie napisanych cyfr od 0 do 9, jest często używany do testowania nowych pomysłów w tej dziedzinie. Badacze MIT wprowadzili technikę "destylowania" olbrzymich zbiorów danych do postaci niewielkich i chcą dowieść jej skuteczności w skompresowaniu MNIST do zaledwie dziesięciu obrazów. Obrazy te nie zostały wybrane z oryginalnego zestawu danych, ale starannie zaprojektowane i zoptymalizowane tak, aby zawierały ilość informacji odpowiadającą pełnemu zestawowi. W rezultacie, po przeszkoleniu wyłącznie na 10 obrazach, model mógł osiągnąć prawie taką samą dokładność, jak ten, który był szkolony na wszystkich obrazach MNIST.
Badacze z Waterloo chcieli posunąć proces destylacji dalej. Jeśli możliwe jest zredukowanie 60 tysięcy obrazów do 10, dlaczego nie wycisnąć ich do pięciu? Zdawali sobie sprawę, że sztuczka polega na tworzeniu obrazów, które łączą wiele cyfr w jedną całość, a następnie wprowadzają je do modelu AI z hybrydowymi, "miękkimi" etykietami. "Jeśli pomyślisz o cyfrze 3, to wygląda ona tak samo jak cyfra 8, ale nie jest podobna do cyfry 7", opowiadała o badaniach Ilia Sucholutsky, badacz z Uniwersytetu Waterloo i główny autor pracy. "Miękkie etykiety próbują uchwycić wspólne cechy. Więc zamiast powiedzieć maszynie: ten obraz to cyfra 3, mówimy: ten obraz to 60 proc. cyfra 3, 30 proc. cyfra 8, a 10 proc. cyfra 0".
Gdy naukowcy z powodzeniem wykorzystali miękkie etykiety do nauki LO-shot na MNIST, zaczęli się zastanawiać, jak daleko ten pomysł może się posunąć. Czy istnieje ograniczenie liczby kategorii, których można nauczyć modelu AI do identyfikacji na podstawie niewielkiej liczby przykładów? Ku zaskoczeniu, odpowiedź wydaje się przecząca. Dzięki starannie zaprojektowanym miękkim etykietom, nawet dwa przykłady mogłyby teoretycznie zakodować dowolną liczbę kategorii.
Aby zrozumieć, jak działa wykorzystywany tu algorytm, weźmy jako przykład zadanie klasyfikacji owoców. Jeśli chce się wytrenować model, aby uchwycić różnicę między jabłkami i pomarańczami, trzeba najpierw wybrać cechy, których chcesz użyć do reprezentacji każdego owocu. Być może wybrane zostaną kolor i waga, więc dla każdego jabłka i pomarańczy podaje się jeden punkt danych z kolorem owocu jako jego wartością x, a wagę jako jego wartość y. Następnie algorytm wykreśla wszystkie punkty danych na wykresie 2D i rysuje linię graniczną prosto na środku między jabłkami i pomarańczami. W tym momencie wykres jest starannie podzielony na dwie klasy, a algorytm może teraz zdecydować, czy nowe punkty danych reprezentują jedną, czy drugą stronę linii, na którą padają.

Destylacja danych, która działa przy projektowaniu miękkich etykiet dla sieci neuronowych, ma poważną wadę - wymaga rozpoczęcia od gigantycznego zbioru danych, aby zmniejszyć go do czegoś bardziej wydajnego. Zatem wciąż pozostaje problem ilości danych, na tym czy na innym etapie.
Mirosław Usidus
Zobacz także:
Sztuczna inteligencja
Co potrafi dobrze wyspany algorytm
Supermózg dla superczłowieka?