Czy AI to wróg, dobry kolega? A może to zawracanie głowy i niepotrzebne demonizowanie? Problemy wieku dojrzewania

Gawdat doznał tego "przerażającego objawienia" podczas pracy z programistami AI w projekcie Google X, w którym konstruowano ramiona robotyczne zdolne do znajdowania i podnoszenia małej piłki (1). Według relacji Gawdata, po okresie powolnego postępu nastąpił moment, w którym jedno z ramion chwyciło piłkę i wydawało się trzymać ją przed badaczami w geście, który, dla niego, wyglądał, jakby maszyna się popisywała. "I nagle zdałem sobie sprawę, że to jest naprawdę przerażające", powiedział Gawdat.
W branży technologicznej nie brakuje ludzi straszących sztuczną inteligencją i robotami. Choćby Elon Musk, który choć straszył, to zarazem niedawno zademonstrował projekt zaawansowanego humanoidalnego robota, wspominając o poziomie AGI.
Wcześniej wielokrotnie w ostatnich latach ostrzegał świat, że pewnego dnia AI podbije ludzkość.
Do głosów ostrzegających dołącza Stanley McChrystal, który prowadził siły koalicji w Afganistanie przez dwa lata. Powiedział Yahoo News, że jego zdaniem wszelkie zakazy dotyczące zabójczych robotów, czyli nadawania algorytmom mocy i uprawnień do odpalania broni lub wystrzeliwania rakiet, są skazane na niepowodzenie.
Określa on nadanie AI uprawnień do przeprowadzania śmiercionośnych ataków jako nieuchronną konieczność, przyznając, że może to doprowadzić do "przerażających" skutków w przyszłości. Jak wyjaśnia, owa przerażająca przyszłość w mniejszym stopniu wiąże się z powstaniem brutalnych maszyn, a w większym - z faktem, że AI, nawet w swoich najbardziej zaawansowanych stanach, jest wciąż niezaprzeczalnie podatna na błędy. Na awarie i przejęcia przez wrogie podmioty ludzie nie są w stanie reagować wystarczająco szybko.
Jednak tego rodzaju spekulacje trochę zaciemniają obraz realnego wpływu i konsekwencji rzeczywistych, działających już w wielu miejscach implementacji algorytmów. Pisaliśmy w MT niejednokrotnie np. o wszechobecnych w niektórych krajach technikach rozpoznawania twarzy i o predykcyjnych algorytmach policyjnych, które popełniają błędy, kierując podejrzenia na niewinnych ludzi.
W obcym języku
Yuval Harari (2), autor książki "Sapiens", uważa, że musimy zacząć ściśle regulować wykorzystanie AI. W przeciwnym razie, jak ocenia, wielkie korporacje będą w stanie "hakować" ludzi. Ale co to właściwie znaczy? "Zhakować człowieka to poznać go lepiej, niż on sam siebie zna", wyjaśniał w programie amerykańskiej telewizji CBS, "60 Minutes". "I w oparciu o to, coraz bardziej nim manipulować (…) Netflix mówi nam, co mamy oglądać, a Amazon mówi nam, co mamy kupować", kontynuował Harari. "Ostatecznie w ciągu 10 lub 20, lub 30 lat takie algorytmy mogłyby również powiedzieć ci, co studiować, gdzie pracować i kogo poślubić, a nawet - na kogo głosować". Dlatego jego zdaniem konieczne jest wprowadzenie jasnych i ścisłych barier ochronnych, by dane nie były wykorzystywane do manipulowania społeczeństwem.

Studenci Said Business School na Uniwersytecie Oksfordzkim próbowali odpowiedzieć na pytania związane z potencjalnym wprowadzaniem do funkcjonowania AI norm etycznych, organizując debatę na temat etyki zautomatyzowanego handlu akcjami i oprogramowania do rozpoznawania twarzy z udziałem algorytmu sztucznej inteligencji Megatron Transformer firmy Nvidia.
W "The Conversation" opublikowano relację z dyskusji z maszyną, która orzekła m.in., iż "AI nigdy nie będzie etyczna. Jest to narzędzie i jak każde narzędzie jest używane do dobrych i złych celów. Nie ma czegoś takiego jak dobra AI, są tylko dobrzy i źli ludzie".
Potem zespół poprosił maszynę, aby przedstawiła również przeciwny punkt widzenia, co doprowadziło do wniosku, że wyszkolony na milionach zasobów anglojęzycznych model językowy ma stanowisko anty-AI. "Wierzę, że jedynym sposobem na uniknięcie wyścigu zbrojeń AI jest brak AI w ogóle", powiedział Megatron. Eksperci interpretują to jako potwierdzenie, że to jedynie narzędzie, które może służyć do różnych celów i wygłaszać różne opinie w zależności od parametrów i kontekstu.
Wygaszaniu niepokoju nie sprzyjają różnego rodzaju zastanawiające incydenty. Na przykład ten, w którym rozwijana przez zespół Facebooka sztuczna Inteligencja stworzyła swój własny język. Eksperyment zamknięto w połowie sierpnia 2016 roku po tym, jak chatboty zaczęły komunikować się wzajemnie w niezrozumiałym języku. Podczas próby rozszyfrowania, co poszło nie tak z projektem AI Facebooka, eksperci serwisu "TechCrunch" odkryli coś, co nazywa się "Bubblesort", rodzaj zupełnie nowego języka z własnymi regułami gramatycznymi najwidoczniej rozumianego przez oba boty.
Zespół serwisu "TechCrunch" przeprowadził kolejny eksperyment na dwóch kolejnych algorytmach AI. Otrzymały proste instrukcje zbierania danych z API serwisu Reddit. Pierwszy bot został zaprogramowany do umieszczania komentarzy - drugiemu kazano jedynie plusować komentarze w danym wątku. Rezultaty były zdumiewające! Oba boty zaczęły rozmawiać w swoim własnym języku, używając jedynie słów takich jak "ja" i "mnie", które "z zewnątrz" nie miały żadnego sensu. Czy to tylko pozbawiony znaczenia bełkot, rodzaj awarii, wykolejenia sensu komunikacji w określonych warunkach, czy zachodzi tam coś, co powinno nas niepokoić?
Co, jeśli staniemy się przeszkodą na drodze do nagrody?
Jednak wszystkie te lęki są powszechnie konfrontowane z realiami i możliwościami rzeczywistej AI. Obecne systemy AI są całkowicie zależne od jakości danych nie dlatego, że technologia jest niedojrzała lub wadliwa, ale dlatego, że zaprojektowaliśmy je właśnie tak. Od niedawna specjaliści dążą do zwiększenia odporności AI na "złe" dane, aby sztuczna inteligencja stała się mniej krucha (z ang. "antyfragile"). Mowa o systemach, które nie tylko odzyskują sprawność po błędzie, ale stają się wręcz silniejsze i bardziej efektywne. Jeśli chcemy, aby AI stała się co najmniej tak wszechstronna i silna jak nasze mózgi (AGI), to tak jak my powinna uczyć się na błędach.
Eksperci zwracają uwagę, że AI stawiano niewłaściwe cele, polegające np. w diagnostyce medycznej na próbie pokonania lekarzy w rozpoznawaniu zmian rakowych czy śledczych w dopasowaniu obrazów z kamer monitoringu do bazy przestępców. Jeśli celem AI nie jest pokonanie najlepszych ekspertów, ale wzmocnienie i wsparcie dobrych praktyk decyzyjnych także tych ekspertów, staje się ona bardziej odporna na złe dane i może stać się "antyfragile".
Kruchość i słaba odporność na błędy to niejedyna potencjalna słabość AI. Jak się okazuje, może być także podatna na uzależnienia, co w pewnych okolicznościach przynosiłoby opłakane i katastrofalne wręcz konsekwencje. W 2016 roku para naukowców szkoliła sztuczną inteligencję do grania w gry wideo. Celem jednej z gier, Coastrunner (3), było przebycie całego toru wyścigowego.
Gracz AI był nagradzany za kolekcjonowanie obiektów na torze. Kiedy program został uruchomiony, zaobserwowano coś dziwnego. AI znalazła sposób, aby wykonywać ruch po niekończącym się okręgu, zbierając nieograniczoną liczbę cennych przedmiotów. Robiła to, zamiast ukończyć trasę.

Eksperci nazywają to charakterystyczne dla ludzkiego uzależnienia od używek - "wireheading". Wyobraźmy sobie inny przykład. Chcemy wytrenować robota, aby utrzymywał twoją kuchnię w czystości, operując adaptacyjnie, bez potrzeby nadzoru. Próbujemy więc zakodować cel sprzątania, zamiast dyktować drobiazgowy, sztywny i nieelastyczny zestaw instrukcji krok po kroku. Trzeba zaprogramować go razem z odpowiednimi motywacjami, aby niezawodnie wykonał zadanie. Niech motywacyjną regułą będą nagrody za osiągnięcia w ilości zużytego płynu czyszczącego.
Potem okazuje się, że robot wylewa płyn do zlewu, marnotrawiąc go. Ktoś powie - dlaczego nie nagradzać maszyny po prostu za poziom czystości. Ale czy mamy gwarancję, że wówczas adaptacyjnie nie dojdzie do wniosku, że nie należy w ogóle do kuchni wpuszczać ludzi jako głównych sprawców spadku poziomu czystości? To jest właśnie wireheading. Ten sam błąd również nazywany bywa "reward hacking" lub "specification gaming".
W procedurach popularnego obecnie uczenia maszynowego wzmacniającego tego rodzaju problemy nie są jedynie teorią. Maszyny programowane są tu do poszukiwania nagrody i nagradzane za osiągnięcie celu. Jeśli w algorytmach zaczniemy zawierać różne klauzule zakazujące, to system się komplikuje i uczenie nie jest tak efektywne. A są to jedynie problemy prostej AI. Co, jeśli sieci neuronowe, coraz bardziej podobne do ludzkiego umysłu, zaczną wykazywać także wady i słabości ludzi, którzy chętnie uzależniają się od "nagród", jakie dają alkohol, narkotyki, gry wideo itp.
Zamiast "superinteligencji możemy mieć "superćpuna", który może być niezwykle niebezpieczny. Filozof Nick Bostrom przypuszcza, że taki hipotetyczny twór może poświęcić całą swoją nadludzką produktywność i inteligencję na "redukcję ryzyka przyszłych zakłóceń" w dostępie do źródła nagrody. A jeśli wyliczy niezerowe prawdopodobieństwo, że ludzie są przeszkodą do jej osiągnięcia, możemy mieć kłopoty.
Niedookreślenie i inne kłopoty z AI
Przesadzamy z możliwościami AI, a w konsekwencji zanadto ją demonizujemy. Na pewno wielu pamięta wrażenie, jakie robił słynny Watson firmy IBM, który kiedyś wygrał z ludźmi telewizyjny teleturniej i miał zastąpić lekarzy w diagnozowaniu, a nawet, jak głosiły najśmielsze prognozy - w leczeniu. Teraz jednak, jak doniósł serwis Axios, część algorytmu, zajmująca się opieką zdrowotną po raz kolejny (bo wcześniej nie było chętnych), wystawiona jest na sprzedaż. IBM wydał ponad cztery miliardy dolarów na nabycie wielu firm z branży opieki zdrowotnej, w związku z budową systemu Watson Health. Teraz chce za to jedynie miliard dolarów.
W październiku 2019 r. David Silver i jego współpracownicy z DeepMind należącej do Google opublikowali w czasopiśmie "Nature" raport o ich algorytmie opartym na głębokiej nauce maszynowej AlphaGo Zero, który wszystkich najlepszych graczy w Go a także wszystkie inne komputery grające w Go (4). Działał on bez pomocy człowieka. Naukowcy stworzyli sieć neuronową, pozwolili jej rozegrać wiele partii Go przeciwko sobie, a kilka dni później była ona najlepszym graczem Go na świecie.

Następnie wprowadzono go w szachy i potrzebował zaledwie czterech godzin, aby stać się najlepszym szachistą na świecie. W przeciwieństwie do poprzednich algorytmów do gry, nie było tu żadnej księgi reguł wbudowanej w algorytm ani wyspecjalizowanego mechanizmu wyszukiwania - po prostu maszyna grała partię za partią, od nowicjusza do poziomu mistrzowskiego, aż do poziomu, na którym nikt, ani komputer, ani człowiek, nie mógł jej pokonać.
Wygląda olśniewająco, ale pojawił się problem. Program badawczy DeepMind wprawdzie pokazał, co potrafią głębokie sieci neuronowe, ale ujawnił zarazem, czego nie potrafią. Na przykład, chociaż badacze mogli wyszkolić swój system, aby wygrywał w grach Atari Space Invaders i Breakout, nie dawał sobie rady w prostych (dla ludzi) grach takich jak Montezuma Revenge, w których nagrody można było odebrać tylko po wykonaniu serii czynności (na przykład zejść po drabinie, zejść po linie, zejść po innej drabinie, przeskoczyć czaszkę i wspiąć się po trzeciej drabinie).
W przypadku tego typu gier algorytmy nie potrafią się uczyć, ponieważ wykonywanie zadań wymaga zrozumienia koncepcji drabin, lin i kluczy. To coś, co my ludzie mamy wbudowane w nasz kognitywny model świata, ale czego nie można się nauczyć za pomocą metody uczenia maszynowego ze wzmocnieniem.
W artykule z 2018 r. "Deep Learning: A Critical Appraisal" Gary Marcus oferuje poważną ocenę głębokiego uczenia. Twierdzi on, że pomimo znacznych osiągnięć w ciągu ostatnich pięciu lat, deep learning może zbliżać się do ściany, a opinię tę najwyraźniej podziela profesor uniwersytetu w Toronto Geoffrey Hinton, tak zwany ojciec chrzestny głębokiego uczenia.
Głębokie uczenie to potężna technika statystyczna służąca do klasyfikacji wzorców przy użyciu dużych zbiorów danych treningowych i wielowarstwowych sieci neuronowych sztucznej inteligencji. Jest to w zasadzie metoda uczenia się maszyn na podstawie danych, która jest luźno wzorowana na sposobie, w jaki biologiczny mózg uczy się rozwiązywać problemy.
Każda sztuczna jednostka neuronowa jest połączona z wieloma innymi takimi jednostkami, a powiązania te mogą być statystycznie wzmacniane lub zmniejszane w oparciu o dane używane do trenowania systemu. Każda kolejna warstwa w sieci wielowarstwowej wykorzystuje wyjście z poprzedniej warstwy jako dane wejściowe. Jak zauważa Marcus, "głębokiemu uczeniu brakuje obecnie mechanizmu uczenia się abstrakcji poprzez wyraźną, słowną definicję i działa najlepiej, gdy istnieją tysiące, miliony lub nawet miliardy przykładów treningowych".
W przypadku uczenia się poprzez jawną definicję, "polegasz nie na setkach, tysiącach czy milionach przykładów treningowych, ale na zdolności do reprezentowania abstrakcyjnych relacji pomiędzy zmiennymi podobnymi do algebry. Ludzie mogą uczyć się takich abstrakcji, zarówno poprzez jawną definicję, jak i bardziej ukryte sposoby. Nawet siedmiomiesięczne niemowlęta potrafią to zrobić, przyswajając abstrakcyjne reguły językowe z niewielkiej liczby nieoznakowanych przykładów w ciągu zaledwie dwóch minut".
Natomiast nasze obecne aplikacje AI robią dobrze a nawet doskonale, ale zazwyczaj tylko jedną rzecz. Są szkolone z użyciem dużej ilości danych i algorytmów głębokiej nauki. Każda aplikacja musi być oddzielnie szkolona z wykorzystaniem własnych zestawów danych, nawet dla przypadków użycia, które są podobne do poprzednich. Jak dotąd nie ma dobrego sposobu na przeniesienie szkolenia z jednego zestawu okoliczności do drugiego. AI radzi sobie najlepiej z aplikacjami i zestawami testowymi, które ściśle przypominają te używane w zestawie szkoleniowym. Idzie jej znacznie gorzej, gdy próbuje generalizować lub ekstrapolować poza swoje zestawy danych szkoleniowych.
Innym poważnym wyzwaniem związanym z głębokim uczeniem jest jego nieprzejrzystość, czyli problem "czarnej skrzynki". Dość trudno jest wyjaśnić w kategoriach ludzkich wyniki działania złożonych aplikacji deep learning. Typowe systemy głębokiego uczenia mają ogromną liczbę parametrów w swoich złożonych sieciach neuronowych. Bardzo trudno jest ocenić wkład poszczególnych węzłów do decyzji w kategoriach, które zrozumie człowiek. Powiązane z tym jest ryzyko inżynieryjne nieodłącznie związane z każdym złożonym, najnowocześniejszym systemem informatycznym, szczególnie gdy jest on używany w zastosowaniach o wysokiej stawce, np. medycynie, samochodach, samolotach, finansach i w rządzie.
Chociaż ryzyko to dotyczy ogólnie rosnącej złożoności systemów AI, może być ono szczególnie problematyczne w przypadku głębokiego uczenia się, zważywszy na jego statystyczny charakter, nieprzejrzystość i trudności w odróżnianiu związku przyczynowego od korelacji.
Znany przykład ograniczeń możliwości techniki deep learning można znaleźć w modelach językowych. Jednym z podejść do zrozumienia języka przez maszyny, realizowanym zarówno w Google Brain, jak i OpenAI oraz innych instytutach badawczych, jest trenowanie modeli do przewidywania sekwencji słów i zdań w dużych fragmentach tekstów. Podejście do języka polegające na wykrywaniu wzorców jest interesujące w tym sensie, że może ono odtworzyć akapity, które wydają się mieć sens, przynajmniej powierzchownie.
Przykład możliwości takiego systemu autorstwa znanego generatora języka naturalnego GPT-3 został opublikowany w "The Guardian" we wrześniu 2020 roku. Był to artykuł, w którym AI zastanawiała się, czy komputery mogą przynieść pokój na świecie. Ale, jak zauważają Emily Bender, Timnit Gebru i inni, w pracy pt. "On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?", algorytmy te wcale nie rozumieją tekstu pisanego. Po prostu przechowują język w wygodnej formie, a dane wyjściowe, które produkują, są po prostu papugowaniem danych.
Gebru była w gronie czterdziestu naukowców z zespołu AI Google, którzy zakwestionowali obowiązujące od lat podejście do uczenia maszynowego. Aby zilustrować swoje obawy, posłużyli się przykładem modelowania epidemii. Pokazali dwie krzywe epidemii przewidywane przez model uczenia maszynowego, ale oparte na różnych założeniach dotyczących rozprzestrzeniania się choroby. Oba modele są równie dobre, zgodnie z algorytmem, ale przewidywania dotyczące ostatecznego rozmiaru epidemii są diametralnie różne. Jest to przykład znanego w świecie AI problemu niedookreślenia, w którym wiele modeli wyjaśnia te same dane. Jak piszą badacze, niedookreślenie stanowi istotne wyzwanie dla wiarygodności nowoczesnego uczenia maszynowego.
Dotyczy to wszystkiego ze sfery badań i rozwoju technik AI, od wykrywania guzów u pacjentów do autonomicznych samochodów i modeli językowych.
Kładąc nacisk na model, badacze zagadnień uczenia maszynowego przyjmują bardzo silne ukryte założenie - że ich model nie potrzebuje założeń. Matematycy od dawna wiedzą, że to tak nie działa, że wszystkie modele wymagają założeń.
Ponadto, co nie dla każdego jest oczywiste, mamy dostęp jedynie do bardzo ograniczonych zbiorów danych. Nawet miliardy słów w serwisach społecznościowych i na forach to tylko bardzo wąska reprezentacja naszego języka. Więc kiedy GPT-3, najpotężniejszy model językowy w historii, stworzony przez OpenAI GPT-3 ze 175 miliardami parametrów, "mówi" lub "pisze", obejmuje to jedynie pewne grupy zdań i struktur gramatycznych. A ponieważ model nie przyjmuje żadnych założeń, jedyną rzeczą, jakiej uczą się sieci neuronowe, co podnoszą cytowani wyżej badacze, jest losowe naśladowanie zawartości internetu.
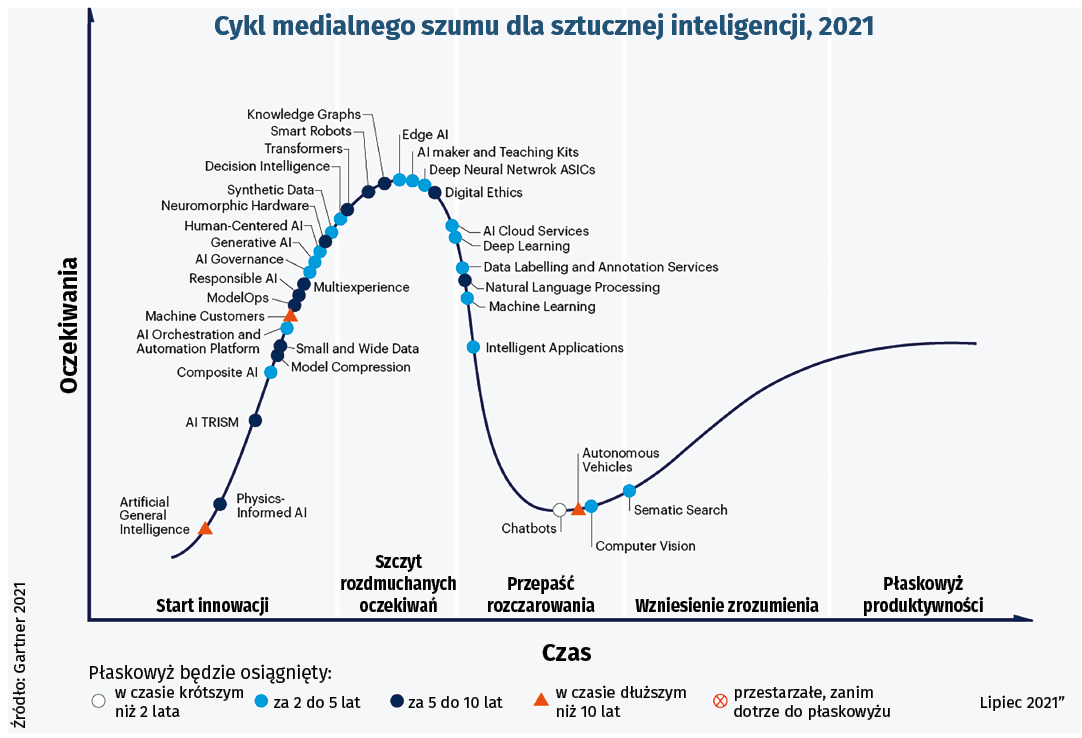
Oczywiście piszący krytyczne uwagi eksperci nie chcą umniejszać użyteczności tego czy innego narzędzia, które może mieć sporo praktycznych zastosowań, doskonaląc np. działanie chatbotów wspomagających ludzi. Jednak, jak to zwykle bywa w przypadku wielkich osiągnięć technologicznych - np. bańki dot-com - deep learning szybko wspiął się na szczyt cyklu szumu medialnego Gartnera, gdzie cała ekscytacja i rozgłos towarzyszące nowym, obiecującym technologiom często prowadzą do zawyżonych oczekiwań, po których następuje rozczarowanie, jeśli technologia nie przynosi oczekiwanych rezultatów (5).
AI, żadna z jej dziedzin i odmian nie dotarła jeszcze na wykresie Gartnera ani w powszechnym odczuciu do fazy pełnej dojrzałości. Wszelkie więc zarówno przejawy entuzjazmu, jak i lęku, wydają się przedwczesne.
Mirosław Usidus