Ekspansja i sprzeciw. Świat danych

Serwis "Finances Online" szacował kilka miesięcy temu łączny wolumen danych wyprodukowanych przez świat do końca 2022 roku na 94 zettabajty danych. Zettabajty to skale tryliardowe wyrażane liczbowo potęgą 1021. Jednocześnie, według oszacowań, 80 proc. tych danych ma charakter nieustrukturyzowany, co nie wchodząc w szczegóły, oznacza, że są duże problemy z ich wykorzystaniem w praktyce.
Aktywność klienta w czasie rzeczywistym
Za każdym razem, gdy wysyłamy e-mail, klikamy w reklamę na Instagramie lub machamy kartą płatniczą, tworzymy porcję cyfrowych danych. Informacje te rozchodzą się po świecie z prędkością jednego kliknięcia, stając się tkanką gospodarki cyfrowej. Swobodny przepływ bitów i bajtów wygenerował ogromną wartość dodaną dla rozwiniętych gospodarek, jednocześnie przyczynił się w dużej mierze do powstania globalnych megakorporacji, takich jak Google i Amazon, i zmienił kształt globalnej komunikacji, handlu, rozrywki i mediów.
Strumienie, rzeki i oceany danych towarzyszą erze informacji od samego początku. W firmach stanowią one podstawę procesów zarządzania pracownikami, pomagają śledzić zakupy i sprzedaż, a także oferują wskazówki dotyczące zachowania klientów.
Sprzedawcy detaliczni monitorują ruchy klientów w sklepie, także za pomocą rozmieszczonych w marketach czujników współpracujących ze smartfonami, co opisywaliśmy w MT (2), a także ich interakcje z produktami. Łączą bogate zasoby danych z zapisami transakcji i przeprowadzają eksperymenty, aby podejmować decyzje dotyczące tego, jakie produkty należy oferować, gdzie je umieścić oraz jak i kiedy dostosować ceny. Metody takie pozwalają zmniejszyć liczbę towarów w magazynie i sprzedawać towary z wysoką marżą. Big data umożliwiają nawet personalizację w czasie rzeczywistym przez śledzenie zachowania poszczególnych klientów na podstawie strumieni kliknięć w Internecie, aktualizowanie ich preferencji i modelowanie ich prawdopodobnych zachowań. Dzięki nim da się rozpoznać, kiedy klienci są bliscy podjęcia decyzji o zakupie i skłonić ich do sfinalizowania transakcji przez łączenie preferowanych produktów. I znów maksymalizuje to sprzedaż i zyski.
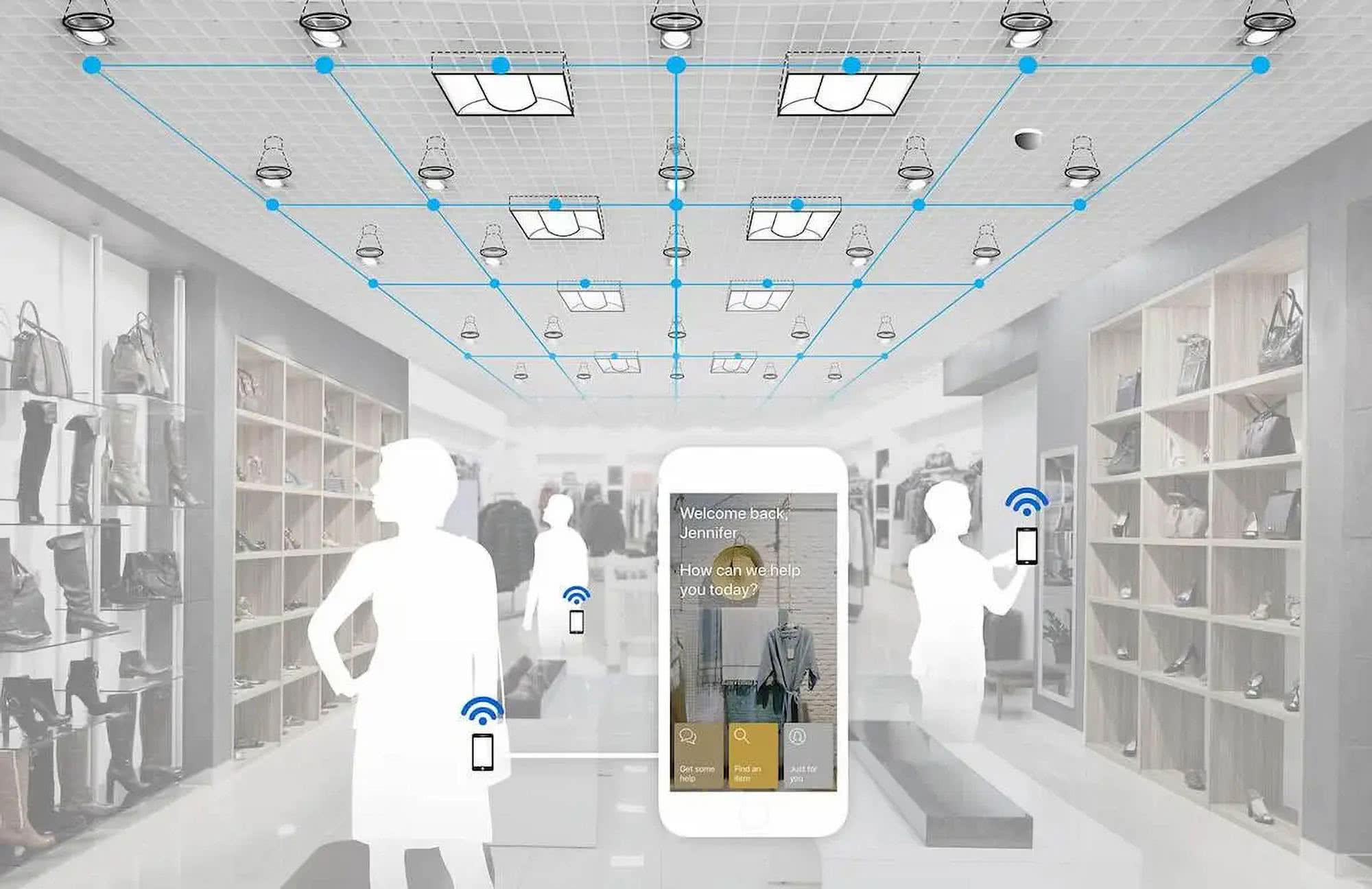
Ubezpieczyciele dostosowują polisy ubezpieczeniowe do każdego klienta, korzystając z drobiazgowych, stale aktualizowanych klienckich profili ryzyka, zmian w majątku, wartości aktywów domowych i innych danych. Dostawcy energii, którzy gromadzą i analizują dane dotyczące kategorii klientów, mogą znacząco zmienić wzorce korzystania z energii w miastach.
W wielu zakładach produkcyjnych algorytmy analizują dane z czujników na liniach produkcyjnych (Internet Rzeczy), tworząc samoregulujące się procesy, które ograniczają ilość odpadów, pozwalają uniknąć kosztownych (a czasem niebezpiecznych) interwencji człowieka i, ostatecznie, podnoszą wydajność. Na "cyfrowych" polach naftowych instrumenty stale odczytują dane dotyczące stanu głowicy odwiertu, rurociągów i systemów mechanicznych (cyfrowe bliźniaki). Informacje te są analizowane przez zespoły komputerów, które przekazują swoje wyniki do centrów operacyjnych działających w czasie rzeczywistym, które dostosowują przepływy ropy w celu optymalizacji produkcji i minimalizacji przestojów (3). Jedna z dużych firm naftowych obniżyła koszty operacyjne i koszty zatrudnienia o 10 do 25 proc., zwiększając jednocześnie produkcję o 5 proc.

Produkty, od kopiarek po silniki odrzutowe, mogą obecnie generować strumienie danych, które mówią wszystko lub prawie wszystko o tym jak działają i pracują. Producenci mogą analizować napływające dane i, w niektórych przypadkach, automatycznie usuwać usterki oprogramowania lub wysyłać przedstawicieli serwisu do naprawy. Niektórzy dostawcy sprzętu komputerowego dla przedsiębiorstw gromadzą i analizują takie dane, aby zaplanować naprawy wyprzedzające, zanim awarie zakłócą pracę klientów. Dane te mogą być również wykorzystywane do wprowadzania zmian w produktach, które zapobiegają przyszłym problemom. Wprawdzie druga strona medalu to zdalna kontrola producenta na czymś, za co klient zapłacił, co opisywaliśmy w jednym z ostatnich numerów MT, to jednak wielu klientów docenia taką "proaktywność".
Skoro mamy tyle danych, to dlaczego na nich nie zarabiać?
Big data tworzy nowe kategorie firm, z modelami biznesowymi opartymi na informacji. Są to nierzadko "stare" firmy, które zorientowały się, że przy okazji swojej podstawowej działalności generują dane, które mają dużą wartość i być może warto to skomercjalizować. Na przykład jedna z firm transportowych zauważyła, że w trakcie prowadzenia działalności gromadzi ogromne ilości informacji na temat globalnych łańcuchów dostaw. Wyczuwając okazję, stworzyła jednostkę, która sprzedaje te dane na potrzeby prognoz biznesowych i gospodarczych.
Jednym ze znanych przykładów transformacji oferty starej firmy na przedsiębiorstwo godne ery informacji jest amerykański koncern General Electric, który działa już ponad 120 lat. Dzięki czujnikom przesyłającym dane z produkowanych przez GE turbin, lokomotyw, silników odrzutowych, urządzeń do obrazowania medycznego i wielu innych, firma ma ogromna bazę wiedzy o tym sprzęcie. Zainwestowała ponad 2 miliardy dolarów w nowe centrum oprogramowania i analiz i sprzedaje rozwiązania analityczne i swoja wiedzę innym firmom przemysłowym. Oferuje software, taki jak platforma Predix do budowania aplikacji Internetu Rzeczy w przemyśle i Predictivity, serię ponad dwudziestu aplikacji do optymalizacji aktywów lub operacji w różnych branżach. Zatem przedsiębiorstwo przemysłowe starego typu stało się dostawcą programistycznych rozwiązań.
Inna znana firma, UPS, również ponad stuletnia historią, już latach 80. XX wieku temu zaczęła śledzić ruch przesyłek i transakcje, gromadząc dane. Jednym z nowszym źródłem dużych danych w UPS są czujniki telematyczne w ponad 46 tysiącach firmowych ciężarówek, monitorujące parametry jak prędkość, kierunek jazdy, hamowanie i wydajność układu napędowego. Fale napływających danych nie tylko pokazują codzienną wydajność, ale także są podstawą do przeprojektowania tras w logistyce. W ramach projektu ORION (On-Road Integrated Optimization and Navigation), gromadzone i analizowane są dane z map online, które przy współpracy z algorytmami optymalizacyjnymi i pozwalają rekonfigurować trasy kierowców w czasie rzeczywistym. Już 2011 r. zaoszczędzono dzięki tym rozwiązaniom 85 mln mil jazy, oszczędzając w ten sposób prawie 30 mln litrów paliwa. Dane te i know-how są oczywiście również bardzo wartościowe dla innych firm.
Jak przetrawić tak wielkie dan(i)e
Pozytywne przykłady to jedno, a wciąż spora nieporadność w powodzi danych to drugie. Badanie firmy Forrester wykazało, że 70 proc. liderów biznesowych w USA gromadzi dane szybciej niż są w stanie je efektywnie analizować i wykorzystywać. Chociaż firmy dysponują ogromnymi ilościami danych, nie mają środków i często wiedzy, jak wydobyć z nich wartość.
Jednocześnie większość organizacji nie ma luksusu budowania systemów danych od podstaw. Mogą one posiadać zgromadzone przez lata dane, które muszą być oczyszczone i przetworzone, aby nadawały się do użytku. Nawet coś tak prostego jak data urodzenia klienta może być przechowywane w kilkunastu różnych i niekompatybilnych formatach. Przez wiele lat podstawową analityką (4) była analityka opisowa. Ale wraz z pojawieniem się zaawansowanych metod analizy, uczenia maszynowego, sztucznej inteligencji, pojawiła się szansa na analitykę w czasie rzeczywistym. Pojawiła się też usługa analytics-as-a-service czyli analiza danych jako usługa, która oferuje pomoc ze strony tych, którzy potrafią radzić sobie z danymi dla tych, którzy mają dane.

We wrześniu 2018 r. profesor Thomas Davenport z Babson College, Harvard Business School i MIT Sloan School of Management podczas Open Data Science w Bostonie przedstawił w skrócie ciekawe ujęcie historii analizy danych biznesowych, począwszy od lat 70. ubiegłego wieku aż po czasy współczesne, dzieląc ją na cztery epoki.
Era pierwsza to analityka rzemieślnicza. Według prof. Davenporta, analityka danych rozpoczęła się w 1975 roku. Ta metodologia była przede wszystkim nastawiona na tworzenie wniosków dla wewnętrznych procesów decyzyjnych przy użyciu niewielkich, ustrukturyzowanych zbiorów danych. Analitycy skupiali się na modelach predykcyjnych opartych na formułowanych przez ludzi hipotezach, których dopracowanie zajmowało znaczną ilość czasu. Oznaczało to, że analityk oferował wsparcie "na zapleczu", jak to określił prof. Davenport.
Era druga to analityka big data. Wraz z rozkwitem Doliny Krzemowej pod koniec lat 90. i na początku XXI wieku, ilość i różnorodność danych wzrosła.
Era trzecia została nazwana przez prof. Davenporta "analityką w gospodarce danymi". W miarę jak ogromne firmy technologiczne znajdowały nowe sposoby zarządzania swoimi ogromnymi zbiorami danych, znajdowały również nowe sposoby ich komercjalizacji. Zaczęły one po prostu sprzedawać dane. Według Davenporta w 2017 roku wkroczyliśmy w kolejną erę analityki, charakteryzującą się coraz większą większą rolą autonomicznego podejmowania decyzji. Na tym etapie maszyny nie tylko przeprowadzają analizę, ale także działają na podstawie spostrzeżeń, podejmując decyzje szybciej i skuteczniej niż jakikolwiek człowiek.
Niektórzy dostrzegają teraz jeszcze inną zmianę, na tyle fundamentalną i dalekosiężną, że nazywa się ją "Analytics 3.0", która polega na stasowaniu wydajnych metod zbierania i analizy danych nie tylko w działalności firmy, ale także w kształtowaniu jej oferty - produktów i usług kupowanych przez klientów.
Koniec swobodnego globalnego przepływu?
Jedni widzą rozwój i świetlane perspektywy, inni - problemy, np. takie, że w ostatnich latach era otwartych dla danych granic dobiega końca. Kraje takie jak Chiny od dawna odgradzały swoje cyfrowe ekosystemy. Teraz jednak i demokracjach obserwujemy nakładanie coraz większej liczby krajowych przepisów dotyczących przepływu informacji, np. w wielkich i demokratycznych Indiach ustawodawcy dążą do uchwalenia ustawy, która ograniczyłaby zakres danych, jakie mogą opuścić kraj zamieszkiwany przez ok. 1,4 miliarda ludzi. Nawet w USA administracja prezydenta Bidena opracowała projekt rozporządzenia, które ma powstrzymać rywali, głównie Chiny, przed uzyskaniem dostępu do amerykańskich danych. Kierowane obawami o bezpieczeństwo i prywatność, jak również interesami ekonomicznymi a czasem tendencjami autorytarnymi i nacjonalistycznymi, rządy coraz częściej ustalają zasady i standardy dotyczące tego, w jaki sposób dane mogą i nie mogą poruszać się przez granice. Celem najczęściej podawanym jest "cyfrowa suwerenność".
Z punktu widzenia zwykłych użytkowników, te nowe ograniczenia raczej nie spowodują zamknięcia używanych na co dzień stron internetowych. Jednak mogą oni stracić dostęp do niektórych usług lub funkcji w zależności od miejsca zamieszkania. Przykładem tylko w obrębie Stanów Zjednoczonych może być Meta, spółka matka Facebooka, która zapowiedziała, że tymczasowo przestanie oferować filtry rozszerzonej rzeczywistości w Teksasie i Illinois, aby uniknąć pozwu na podstawie przepisów regulujących wykorzystanie danych biometrycznych w tych stanach.
Za punkt zwrotny w podejściu do danych i polityki Big Tech rodem z USA uważa się ujawnienie przez Edwarda Snowdena w 2013 r. dokumentów, które opisywały szeroko zakrojoną amerykańską inwigilację komunikacji cyfrowej. W Europie wzrosły obawy, że zależność od amerykańskich firm sprawia, że Europejczycy są narażeni na amerykańskie szpiegowanie. Doprowadziło to do wieloletnich bojów prawnych o prywatność w sieci oraz do transatlantyckich negocjacji w sprawie ochrony komunikacji i innych informacji przekazywanych amerykańskim firmom.
Stany Zjednoczone popierają podejście, które pozwala na swobodny przepływ danych pomiędzy demokratycznymi krajami. Chiny a także Rosja i inne kraje uznawane za niedemokratyczne odgradzają się od Internetu i utrzymują przepływ informacji pod kontrolą m.in. po to, aby inwigilować obywateli i namierzać dysydentów. Unia Europejska dąży do kontroli nad danymi Europejczyków, w pozytywnym i negatywnym tego słowa znaczeniu. W UE gospodarka danymi osobowymi od 2018 r. musi spełniać wymogi rozporządzenia o ochronie danych (GDPR).
W miarę wprowadzania nowych przepisów, branża technologiczna podejmowała z nimi walkę prawną i lobbystyczną. Przedstawiciele Amazona, Apple, Google, Microsoftu i Meta argumentowały, że gospodarka internetowa jest napędzana przez swobodny przepływ danych, zatem, jeśli firmy Big Tech będą musiały przechowywać je wszystkie lokalnie, nie będą mogły oferować tych samych produktów i usług na całym świecie. Jednak część europejskich krajów była nieugięta. We Francji i Austrii, klientom oprogramowania do pomiaru internetu Google Analytics, które używane jest przez wiele stron internetowych do zbierania danych o oglądalności, zakomunikowano, aby nie używali więcej tego programu, ponieważ może on narazić dane osobowe Europejczyków na amerykańskie szpiegostwo. Rząd francuski kilkanaście miesięcy temu zerwał umowę z Microsoftem na obsługę danych zdrowotnych, po krytyce publicznej za przyznanie przez władze kontraktu amerykańskiej firmie. Urzędnicy zobowiązali się do współpracy z lokalnymi firmami.
Max Schrems, austriacki działacz na rzecz ochrony prywatności, który wygrał proces przeciwko Facebookowi w sprawie praktyk platformy społecznościowej w zakresie udostępniania danych, przewiduje, że umowa o ochronie danych między USA a UE, zaproponowana przez prezydenta Bidena, zostanie odrzucona przez Europejski Trybunał Sprawiedliwości, ponieważ nadal nie spełnia standardów prywatności UE.
Microsoft i Amazon starają się przystosować, oferując nowe usługi, które pozwalają firmom przechowywać dane na określonym terytorium. Alphabet z kolei podpisał we Francji, Hiszpanii i Niemczech, umowy z lokalnymi dostawcami usług dla chmury, tak aby lokalna firma nadzorowała ich dane podczas korzystania z produktów Google. Wydaje się jednak, że zasadnicza sprzeczność między interesami "gospodarki opartej na danych" a dążeniami dostarczycieli tych danych, niezależnie od tego, czy pod hasłami "narodowej suwerenności" czy ochrony prywatności osobistej, będzie się pogłębiać.
Mirosław Usidus