Maszyny tłumaczące języki. Algorytm przysięgły

Oprogramowanie do tłumaczenia maszynowego (często używa się skrótu MT, pochodzącego od angielskiego "machine translation"), choć bardzo pomocne w zwiększaniu wydajności pracy tłumaczy i tłumaczeniu dużych ilości tekstów, wciąż nie zawsze spełnia standardy jakości oczekiwane od usług tłumaczeniowych. Otwiera to pole do popisu dla nowych pomysłów i rozwiązań, które niekoniecznie muszą być oparte na potędze i pieniądzach Big Tech.
Sto miliardów słów dziennie
Tłumaczenie maszynowe (1) to zautomatyzowana konwersja jednego języka na drugi. Oprogramowanie do tłumaczenia maszynowego konwertuje tekst z języka źródłowego i tworzy jego odpowiednik w języku docelowym.
Na podstawowym poziomie MT dokonuje automatycznej zamiany słów w jednym języku na słowa w innym, ale zastosowanie wyłącznie takiego mechanizmu rzadko daje dobre tłumaczenie. Potrzebne jest rozpoznanie całych fraz i ich najbliższych odpowiedników w języku docelowym. Dodatkowo nie wszystkie słowa w jednym języku mają swoje odpowiedniki w innym języku, a wiele słów ma więcej niż jedno znaczenie.
Współczesne oprogramowanie do tłumaczenia maszynowego często pozwala na dostosowanie do potrzeb użytkownika według dziedziny lub profilu tematycznego (np. raporty pogodowe), poprawiając wydajność poprzez ograniczenie zakresu dopuszczalnych zamienników. Technika ta jest skuteczna szczególnie w dziedzinach, w których używa się języka formalnego lub szablonów. Maszynowe tłumaczenie dokumentów rządowych i prawnych łatwiej daje użyteczne wyniki niż maszynowe tłumaczenie rozmów lub mniej standardowych tekstów. Poprawa jakości tłumaczenia może być oczywiście osiągnięta przez interwencję człowieka, co oznacza także, że MT okazuje się użyteczne jako narzędzie wspomagające pracę tłumaczy.

Aplikacjom oferującym MT towarzyszą dziś takie funkcje jak zamiana tekstu na mowę lub w drugą stronę - konwersja słowa mówionego do tekstu. W połączeniu z systemami maszynowego tłumaczenia mogą pozwolić na tłumaczenie symultaniczne w trakcie wystąpień lub rozmów w czasie rzeczywistym. Microsoft już kilka lat temu zaczął wprowadzać takie funkcje dla niektórych par języków w swoim oprogramowaniu telekonferencyjnym Skype (2). W terenie pośredniczy w tym zwykle smartfon lub inne przenośne urządzenie, choćby megafon jak w przypadku Megahonyaku firmy Panasonic (3) lub małych słuchawek Pilot firmy Waverly Labs. Trudno te rozwiązania uznać za już w pełni dojrzałe i działające bez zarzutu, ale stanowią obiecujący kierunek rozwoju. Pomocna w wielu sytuacjach w połączeniu z zamianą tekstu na mowę i odwrotnie może być oferowana np. przez Google Translate funkcja wykrywania języka w czasie rzeczywistym; np. notorycznie nie odróżniający języków słowiańskich przybysze np. z zachodniej Europy mogą dzięki takim funkcjom ustawić swoje urządzenie tłumaczące na właściwa parę.

Dziś wykorzystanie tłumaczenia maszynowego stało się powszechne. Google Translate podaje, że tłumaczy ponad 100 miliardów słów dziennie. Powszechną praktyką jest też tłumaczenie treści stron internetowych na inne języki. W ten sposób np. firmy nie tylko są w stanie rozszerzyć się na nowe rynki międzynarodowe, ale również pomagają dotrzeć do grup, które wcześniej nie miały dostępu do informacji w Internecie. Znane usługi tłumaczenia maszynowego oferują interfejsy dla programistów (API), które pozwalają wprowadzić funkcje tłumaczenia do stron, aplikacji, sklepów i innych usług sieciowych firm. Najbardziej znane produkty tego rodzaju to Google Cloud - Platforma Translation AI, platforma Deepl, AWS - Platforma Amazon Translate, platforma Unbabel, Microsoft Azure - platforma Microsoft Translator, platforma Yandex Translate, IBM Watson - platforma Watson Language Translator, platforma Lingvanex, platforma ModernMT i platforma SYSTRAN.
Maszyny mogą pracować bez przerwy przez długi czas, dostarczając wyniki niemal natychmiast. A firmy cenią szybkość i oszczędności w kosztach. Tłumaczenie maszynowe im na to pozwala z malejącym ryzykiem dla jakości przekładu, choć pomimo poprawy wyników wśród specjalistów i firm nadal panuje zazwyczaj przekonanie, że nie można mu całkowicie ufać, bo nie jest w stanie zastąpić tłumaczenia wykonywanego przez człowieka. Niektóre firmy decydują się na "hybrydowe" tłumaczenia, wykorzystując MT do wstępnego tłumaczenia, a następnie przekazując wynik tłumaczom ludzkim w celu dalszej poprawy jakości i dokładności.
"Tłumaczenie maszynowe nie jest warte dużych inwestycji"
Koncepcja tłumaczenia automatycznego wywodzi się z prac arabskiego kryptografa Al-Kindiego. Po Al-Kindim postęp w dziedzinie tłumaczenia automatycznego postępował powoli przez wieki aż do lat 30. XX wieku. Jeden z najbardziej znaczących patentów w tej dziedzinie pochodzi od radzieckiego naukowca, Piotra Trojańskiego, z 1933 roku, który zaprezentował w Radzieckiej Akademii Nauk swoją "maszynę do wyboru i drukowania słów podczas tłumaczenia z jednego języka na drugi".
Tłumacz maszynowy Trojańskiego składał się z maszyny do pisania, kamery filmowej i zestawu kart językowych. Osoba posługująca się językiem oryginału organizowała karty tekstowe w logicznej kolejności, robiła zdjęcie i wprowadzała cechy morfologiczne tekstu do maszyny do pisania. Następnie maszyna tworzyła zestaw klatek, efektywnie tłumacząc słowa za pomocą taśmy i filmu aparatu. Na koniec redaktor biegły w języku docelowym przeglądał tłumaczenie i upewniał się, że zostało ono ułożone w odpowiedniej kolejności.
W 1954 roku firma IBM rozpoczęła eksperyment, w którym jego system komputerowy IBM 701 dokonał pierwszego na świecie automatycznego tłumaczenia tekstu rosyjskiego na angielski. Badania i eksperymenty trwały na całym świecie, jednak w 1966 r. amerykański Komitet Doradczy ds. Automatycznego Przetwarzania Języka (ALPAC) wydał oświadczenie głoszące, że tłumaczenie maszynowe nie jest warte dużych inwestycji, ponieważ nie jest na tyle efektywne, aby zrekompensować koszty rozwoju.
Aż od końca lat 80. postęp MT rzeczywiście nie był imponujący. Kiedy jednak moc obliczeniowa komputerów wzrosła i potaniała, zaczęto szybko rozwijać modele statystyczne. Powstały pierwsze komputerowe firmy tłumaczeniowe, np. Trados. W 1996 roku w internecie udostępniono wersje online znanego od lat 60. narzędzia SYSTRAN, oferując bezpłatne tłumaczenie krótkich tekstów. Inną wówczas znaną bezpłatną usługą tłumaczeniową w sieci był Globlink Lernout & Hauspie. W kolejnych latach pojawiły się usługi tłumaczenia tekstu/SMS dla telefonów komórkowych w Japonii (2008) oraz telefon komórkowy z wbudowaną funkcją tłumaczenia mowy na język angielski, japoński i chiński (2009). W 2012 Google ogłosił, że jego usługa Translate tłumaczy mniej więcej tyle tekstu, aby wypełnić milion książek w ciągu jednego dnia.
Od gramatyki do sztucznej inteligencji
Choć definicja MT, mówiąca o konwersji jednego języka na inny, brzmi dość prosto, to jednak mechanizmy, na których się opiera, pełne są skomplikowanych procesów, które rozwijały się od mniej więcej połowy XX wieku.
Na początku było tłumaczenie maszynowe oparte na regułach (RBMT), przy założeniu, że języki zawierają reguły gramatyczne, syntaktyczne i semantyczne, które nimi rządzą. Reguły te są predefiniowane przez ludzkich ekspertów zarówno w języku źródłowym, jak też docelowym, i w dużej mierze opierają się na rozbudowanym słowniku dwujęzycznym. Tłumaczenie tego typu odbywa się w trzech fazach: analizy, transferu i generacji. Generowanie tłumaczeń tą metodą jest często czasochłonne i kosztowne, ale zastosowane kompleksowo daje wysoką jakość wyników. Metoda sprawdza się najlepiej przy tłumaczeniu między językami, których reguły są dynamiczne i abstrakcyjne.
Istnieją trzy rodzaje systemów RBMT. Bezpośrednia translacja (ang. direct machine translation) jest najbardziej elementarną formą tłumaczenia maszynowego. Używając prostej struktury reguł, rozbija zdanie źródłowe na słowa, porównuje je z wprowadzonym słownikiem, a następnie dostosowuje wyjście na podstawie morfologii i składni. Metoda ta jest czasochłonna, ponieważ wymaga napisania reguł dla każdego słowa w słowniku. Bezpośrednie tłumaczenie maszynowe było świetnym punktem wyjścia, ale od tego czasu odeszło do lamusa i zostało zastąpione przez bardziej zaawansowane techniki.
Kolejna metoda RBMT, oparta na transferze, rezygnuje z tłumaczenia słowo po słowie, najpierw organizując strukturę gramatyczną języka źródłowego. Tłumaczenie maszynowe oparte na transferze dzieli się na trzy etapy: maszyna analizuje język źródłowy, aby zidentyfikować jego zestaw reguł gramatycznych, struktura zdania jest następnie przekształcana w formę zgodną z językiem docelowym, i w końcu w trzecim etapie zachodzi generowanie - po ustaleniu odpowiedniej struktury, maszyna produkuje przetłumaczony tekst.
Międzyjęzykowe tłumaczenie maszynowe to metoda tłumaczenia tekstu z języka źródłowego na interlingua (reprezentację pośrednią), sztuczny język opracowany w celu tłumaczenia słów i znaczeń z jednego języka na drugi, a następnie konwersję tłumaczenia interlingua na język docelowy. Metoda ta jest czasami mylona z systemem tłumaczenia maszynowego opartego na transferze. Jednak międzyjęzykowe tłumaczenie maszynowe zapewnia szerszy zakres zastosowań, może on obejmować wiele języków docelowych. Główną zaletą interlingua jest to, że programiści muszą tworzyć reguły tylko między językiem źródłowym a interlingua. Wadą jest to, że stworzenie wszechstronnej interlingua jest niezwykle trudne.
Tłumaczenie maszynowe oparte na przykładach (EBMT) jest metodą tłumaczenia maszynowego, która wykorzystuje teksty równoległe (korpusy dwujęzyczne). Porównuje się tę metodę z Kamieniem z Rosetty, starożytnym artefaktem, zawierającym dekret króla Ptolemeusza V Epifanesa w trzech odrębnych językach. Kamień z Rosetty (4) walnie przyczynił się do rozszyfrowania hieroglifów egipskich, gdyż zawierał ich tłumaczenie na starogrecki.

W 1984 r. Makoto Nagao z uniwersytetu w Kioto odkrył, że zamiast tłumaczenia słowo w słowo, lepsze tłumaczenie (przynajmniej w parze japoński-angielski) zapewni metoda fraza po frazie. W tej metodzie, im więcej fraz w bazie danych, tym łatwiej jest systemowi znaleźć słowo zastępcze. Na przykład, jeśli proste wyrażenie "Chcę pójść do kina" zostało już przetłumaczone na język docelowy, to tłumaczenie "Chcę pójść na spacer" nie wymaga przetłumaczenia całego zdania. Wystarczy znaleźć odpowiednik "na spacer". Metoda ta znacznie zwiększyła dostępność tłumaczenia maszynowego, ponieważ złożone reguły językowe są już zazwyczaj wbudowane w każde wyrażenie.
Około pół dekady po wprowadzeniu EBMT firma IBM zaprezentowała system tłumaczenia maszynowego całkowicie odmienny od systemów RBMT i EBMT. System tłumaczeń statystycznych (SMT) nie opiera swoich tłumaczeń na regułach czy lingwistyce. Zamiast tego system podchodzi do tłumaczenia języka poprzez analizę wzorców i prawdopodobieństwa.
System SMT wykorzystuje model językowy, który oblicza prawdopodobieństwo użycia frazy przez użytkownika języka. Następnie dopasowuje dwa języki, które zostały podzielone na słowa, porównując prawdopodobieństwo, że określone znaczenie było zamierzone. Na przykład SMT obliczy prawdopodobieństwo, że greckie słowo γραφείο (grafeío) ma być przetłumaczone na angielskie słowo "office" lub "desk". Metodologia ta jest również stosowana w przypadku kolejności słów. Decyzje nie są podyktowane zasadami ustalonymi przez programistę. Tłumaczenia opierają się na kontekście zdania. Maszyna określa, że jeśli jedna z form jest częściej używana, to najprawdopodobniej jest to poprawne tłumaczenie. Metoda SMT okazała się znacznie dokładniejsza i mniej kosztowna niż systemy RBMT i EBMT. System opierał się na dużej ilości tekstu, aby stworzyć wiarygodne tłumaczenie, więc lingwiści nie musieli wykorzystywać swojej wiedzy.
Pierwszy statystyczny system tłumaczenia maszyn-wego zaprezentowany przez IBM, zwany Modelem 1, dzielił każde zdanie na słowa. Słowa te były następnie analizowane, liczone i nadawano im wagę w porównaniu z innymi słowami, na które można je przetłumaczyć, bez uwzględniania kolejności słów. Aby ulepszyć ten system, IBM opracował Model 2, który uwzględniał składnię, zapamiętując, gdzie w przetłumaczonym zdaniu znajdują się słowa. Model 3 jeszcze bardziej rozbudował system, wprowadzając dwa dodatkowe kroki. Model 4 zaczął uwzględniać układ słów. Ponieważ języki mogą mieć różną składnię, szczególnie jeśli chodzi o przymiotniki i rozmieszczenie rzeczowników, Model 4 przyjął system kolejności względnej.
SMT oparte na słowach wyprzedziło poprzednie systemy RBMT i EBMT, ale też wymagało udoskonaleń. Metoda bazująca na słowach została szybko wyparta przez metodę opartą na frazach. System ten jest zbudowany na ciągłej sekwencji "n" elementów z bloku tekstu lub mowy. W terminologii lingwistyki komputerowej te bloki fraz nazywane są n-gramami. Celem metody opartej na frazach jest rozszerzenie zakresu tłumaczenia maszynowego o n-gramy o różnej długości. Jednak maszyna nie oblicza n-gramów w taki sam sposób, jak my przetwarzamy frazy. Zamiast używać fraz językowych, jak to robimy w normalnej mowie, maszyna podchodzi do swojego statystycznego rankingu fraz, ponieważ normalne frazy nie zawsze są skonstruowane przy użyciu standardowej składni. Inną formą SMT było tłumaczenie oparte na składni, jednak nie udało mu się zdobyć znaczącej popularności.
Po wprowadzeniu tych dodatków, tłumaczenie maszynowe uległo zauważalnej poprawie. Metoda ta została szybko przyjęta przez największe firmy technologiczne, takie jak Google, Microsoft i Yandex. Przez ponad dekadę tłumaczenie maszynowe oparte na frazach było standardem w tłumaczeniu języków, spychając w cień starsze metody. Jednak SMT ma wady. Jedną z największych jest to, że przy próbie tłumaczenia tekstu, który różni się od zasobu w korpusie językowym, na którym system jest zbudowany, napotykamy liczne anomalie. Systemowi problemy sprawiają idiomy i kolokwializmy. Takie podejście jest szczególnie niekorzystne, gdy chodzi tłumaczenie mało znanych lub rzadkich języków. Niezdolność SMT do skutecznego tłumaczenia języka potocznego oznacza, że jego zastosowanie poza specyficznymi dziedzinami techniki jest ograniczone. Choć jest on znacznie lepszy od RBMT, błędy w poprzednim systemie można było łatwo zidentyfikować i naprawić. Systemy SMT są trudne do naprawienia w przypadku wykrycia błędu, ponieważ cały system musi być ponownie przeszkolony.
Systemy SMT oparte na frazach królowały do ok. 2016 roku, w którym to momencie najważniejsze w branży firmy przestawiło swoje systemy na neuronowe tłumaczenie maszynowe (NMT). Pod względem operacyjnym NMT nie jest wielkim odstępstwem od SMT. NMT działa poprzez dostęp do rozległej sieci neuronowej, która w przeciwieństwie do SMT jest szkolona do czytania całych zdań. Pozwala to na utworzenie bezpośredniego "kanału" między językiem źródłowym a docelowym. Zasady rekurencyjnych sieci neuronowych powalają usunąć ograniczenia dotyczące długości tekstu, dzięki czemu tłumaczenie zachowuje swoje prawdziwe znaczenie.
Stosowana w NMT architektura kodera-dekodera działa poprzez zakodowanie języka źródłowego w wektorze kontekstu. Wektor kontekstu jest reprezentacją tekstu źródłowego o stałej długości. Następnie sieć neuronowa wykorzystuje system dekodujący do przekształcenia wektora kontekstu na język docelowy. Mówiąc inaczej, strona kodująca tworzy opis tekstu źródłowego, rozmiar, kształt, działanie i tak dalej. Strona dekodująca odczytuje ten opis i tłumaczy go na język docelowy. Ten mechanizm uwagi szkoli modele do analizowania sekwencji dla słów głównych, zaś sekwencja wyjściowa jest dekodowana.
Pierwotnie RNN była jednokierunkowa, biorąc pod uwagę tylko słowo poprzedzające słowo kluczowe. Następnie stała się dwukierunkowa, uwzględniając również słowo poprzedzające i następujące po nim. W końcu NMT wyprzedził możliwości SMT opartego na frazach. NMT zaczął produkować tekst wyjściowy, który zawierał mniej niż połowę błędów kolejności słów i prawie 20% mniej błędów słownych i gramatycznych niż tłumaczenia SMT. NMT jest zbudowany z myślą o uczeniu się maszynowym. Im więcej korpusów zostanie wprowadzonych do RNN, tym większa będzie jego zdolność do adaptacji, co zaowocuje mniejszą liczbą błędów.
Jedną z głównych zalet NMT w porównaniu z systemami SMT jest to, że tłumaczenie pomiędzy dwoma językami spoza światowej lingua franca nie wymaga znajomości angielskiego. W przypadku SMT język źródłowy był najpierw konwertowany na język angielski, zanim został przetłumaczony na język docelowy. Ta metoda prowadziła do utraty jakości z oryginalnego tekstu do angielskiego tłumaczenia i dodatkowego miejsca na błędy w tłumaczeniu z angielskiego na język docelowy. System NMT jest dodatkowo wzbogacony o funkcję crowdsourcingu. Kiedy użytkownicy wchodzą w interakcję z Google Translate online, otrzymują podstawowe tłumaczenie wraz z kilkoma innymi potencjalnymi tłumaczeniami. W miarę jak coraz więcej osób wybiera jedno z nich, system zaczyna się uczyć, które tłumaczenie jest najdokładniejsze.
Zazwyczaj tłumaczenia oparte na sieciach neuronowych obliczają prawdopodobieństwo użycia słowa lub frazy na bazie istniejących tekstów dwujęzycznych. Jednak w przypadku języków o niskich zasobach czerpią paralele z istniejącego leksykonu i wykorzystują je do budowy systemu tłumaczeniowego, eliminując potrzebę wprowadzania nowych danych. Umożliwiają bezpośrednie tłumaczenie zerowe. Tłumaczenia są wykonywane bezpośrednio ze źródła na języki docelowe, nawet w przypadku, gdy nie istnieje żaden translator językowy między tymi dwoma językami. Jest to zasilane przez technologię głębokiego uczenia się.
Techniki te wykorzystywane są na najbardziej znanych dziś platformach tłumaczeniowych, Google Translate czy Deepl. Apple wykorzystuje rekurencyjne sieci neuronowe (RNN) jako podstawę oprogramowania do rozpoznawania mowy przez asystenta Siri.
NMT są drogie w porównaniu z innymi systemami tłumaczenia maszynowego. Wymagają one również więcej szkoleń niż ich odpowiedniki SMT, a ponadto nadal napotykamy problemy jakościowe, gdy mamy do czynienia z niejasnymi lub nowymi słowami. W NMT, aby zapobiec bezsensownym tłumaczeniom, potrzebna jest wciąż wysoka jasność w tekście źródłowym, taka samo jak w innych systemach tłumaczenia maszynowego. Systemy z AI wciąż wymagają wkładu człowieka. Szkolenie programu wymaga wielu roboczogodzin ludzkiego zespołu, zanim będzie mógł efektywnie pracować. Ważna jest też weryfikacja ludzkim okiem i umysłem przetłumaczonego dokumentu w celu uzyskania pewności, że tekst ma sens.
W celu złagodzenia części najczęstszych problemów występujących w metodach tłumaczenia maszynowego podjęto próby połączenia niektórych ich funkcji lub całych systemów. Podejście "wielosilnikowe" łączy dwa lub więcej metod i systemów tłumaczenia maszynowego w sposób równoległy. Wynik w języku docelowym jest kombinacją ich wyników końcowych. Alternatywą dla podejścia "wielosilnikowego" jest podejście "wieloprzebiegowe", czyli seryjne tłumaczenie języka źródłowego. Język źródłowy jest przetwarzany np. przez system RBMT, a następnie przekazywany do SMT, aby stworzyć wyjście języka docelowego (5).
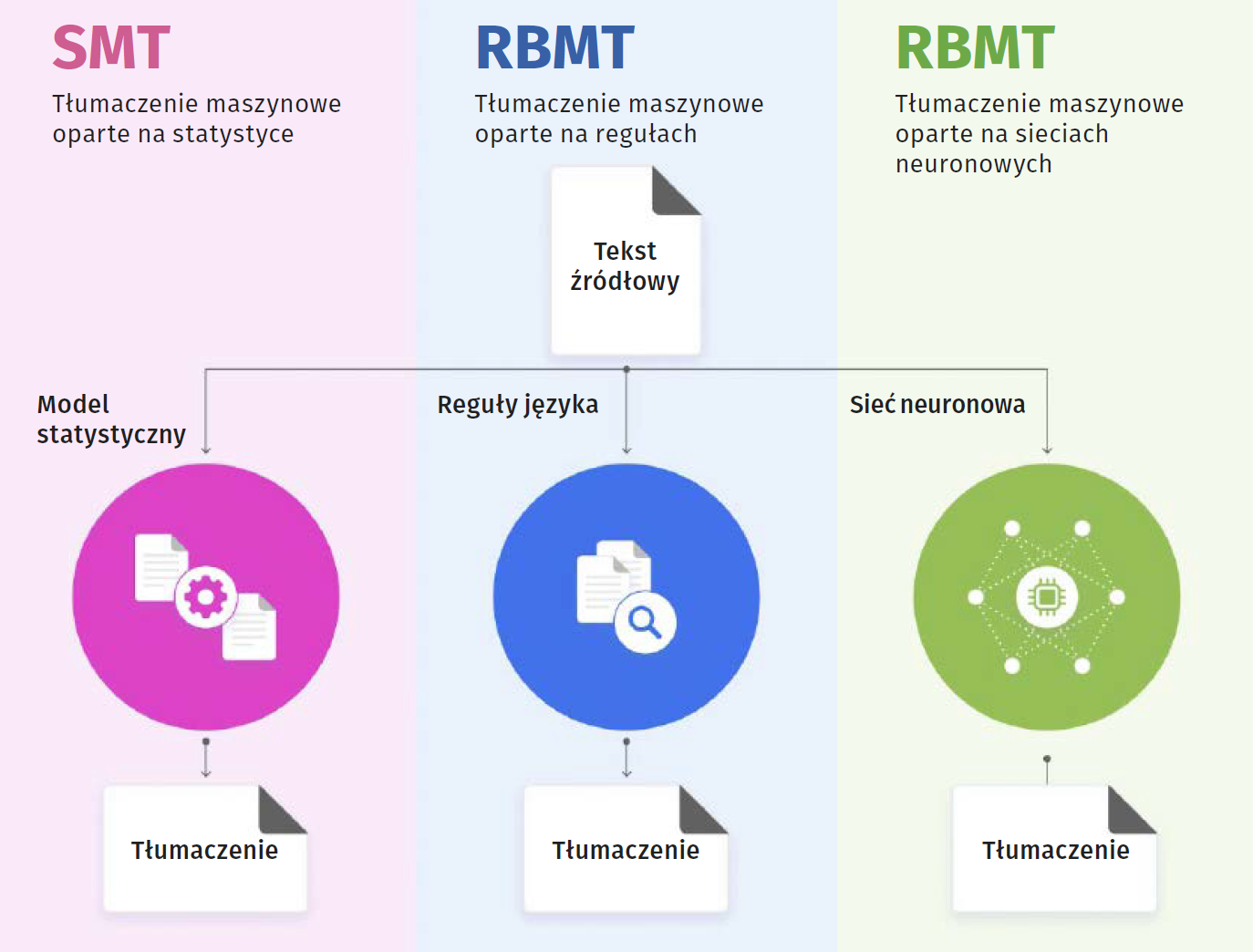
Metoda oparta na zaufaniu podchodzi do tłumaczenia inaczej niż pozostałe systemy hybrydowe, ponieważ nie zawsze wykorzystuje wielokrotne tłumaczenie maszynowe. Ten typ systemu zazwyczaj przepuszcza język źródłowy przez system NMT, a następnie otrzymuje wynik. Jeśli wynik nie jest zadowalający, jest przekazywany do oddzielnego systemu SMT, który ma szlifować jakość tłumaczenia.
Jakość najważniejsza
Typowe, najczęściej spotykane wady systemów MT to np. gdy nie radzi sobie z niektórymi frazami z powodu braku kontekstu. Ma zwykle trudności z dokładnym tłumaczeniem niuansów i slangu. Problemy pojawiają się również przy tłumaczeniu skomplikowanych lub specyficznych dla branży terminów (np. terminologii medycznej). Często treść uzyskana w tłumaczeniu w języku docelowym może wydawać się poszarpana i nieskładna.
Jakość przetłumaczonej treści jest najważniejszym aspektem tłumaczenia. To na jej podstawie przygotowuje się rankingi i wszelkiego rodzaju badania porównawcze maszynowych narzędzi tłumaczących (6). Dlatego lingwiści i programiści pracują nad narzędziami, które mogą oceniać jakość tłumaczeń, od czasów początkowych technik tłumaczenia maszynowego w latach 50. XX wieku.
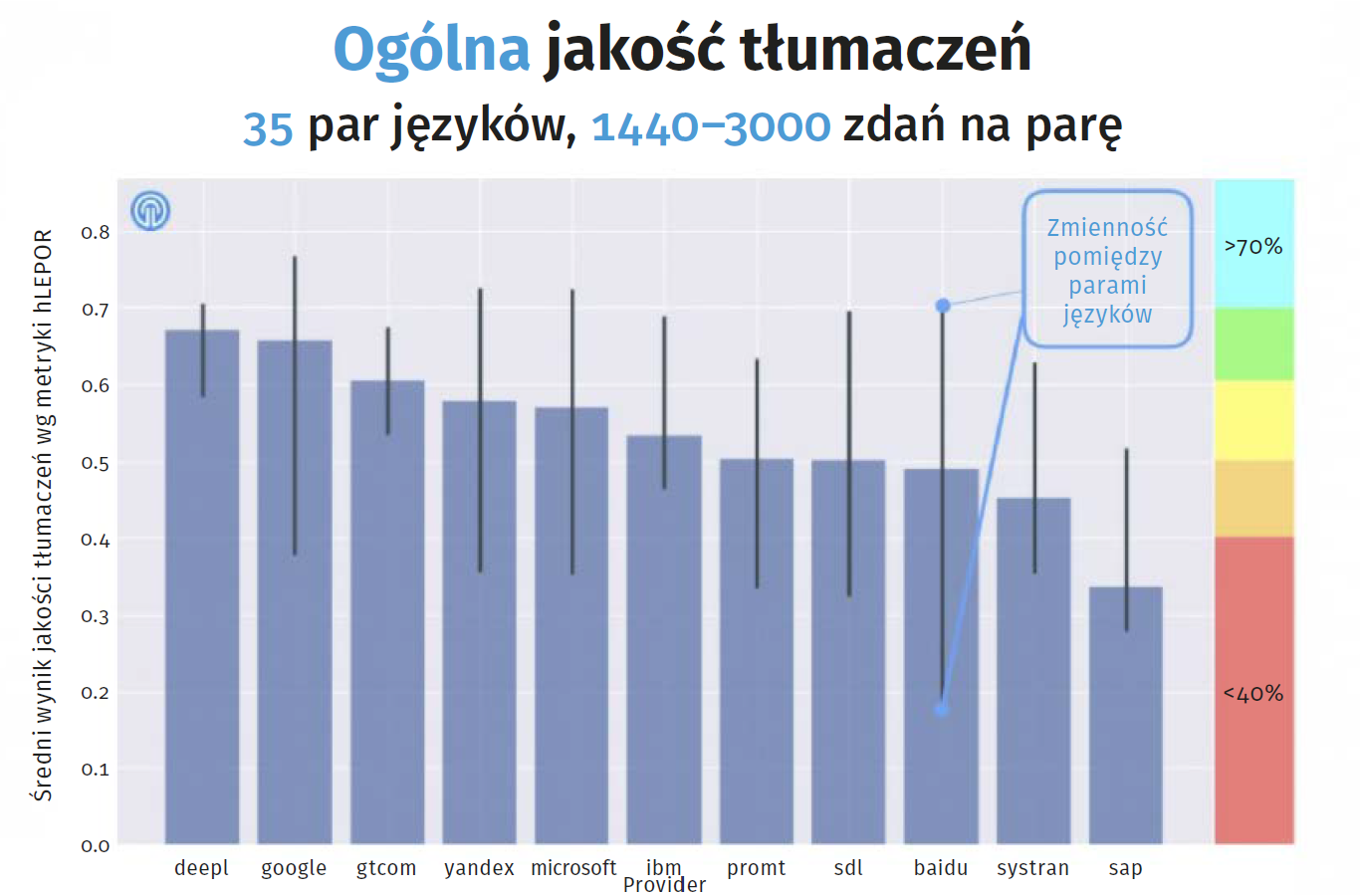
przez firmę tłumaczeniową Intento
W ogólnym ujęciu praktykuje się dwa podejścia w weryfikacji jakości tłumaczeń. Pierwsze to ocena glass box, która mierzy jakość tłumaczenia na bazie wewnętrznych mechanizmów systemu tłumaczeniowego. Drugie podejście to metoda czarnej skrzynki, opierająca się wyłącznie na jakości danych wyjściowych, które stanowi obecnie bardziej powszechny paradygmat.
Ocena opiera się na z góry ustalonym zestawie. Zestaw ten składa się ze zdań w języku źródłowym i ich tekstów partnerskich w języku docelowym. Przetłumaczone teksty są następnie porównywane z tymi zestawami i jeśli mają ten sam styl, zostanie wykryte dopasowanie. W najprostszej procedurze ludzie po prostu czytają końcowy tekst, aby sprawdzić jego poprawność. Głównymi wskaźnikami podczas oceny są płynność i zgodność ze znaczeniem tekstu źródłowego. Przy sprawdzaniu płynności tekst źródłowy jest nieistotny. Następnie tekst jest porównywany z oryginałem, aby upewnić się, że nie odbiega on zbytnio od przesłania materiału źródłowego. Inna technika, ocena automatyczna, w dużej mierze opiera się na wcześniej istniejących tłumaczeniach, z którymi wynik jest porównywany.
Czy tłumaczenie maszynowe może zastąpić tłumaczenie ludzkie? Tak. Jest już sporo przypadków, w których MT jest lepszym rozwiązaniem. W wielu językach i formach komunikacji technicznej, specjalistycznej, opartej na szablonach i standardach, np. w świecie finansów, raportowaniu wyników od spółek giełdowych po sport, zautomatyzowane tłumaczenie doskonale się sprawdza. Jednak przy mniej standardowej spontanicznej, opartej na języku potocznym lub kreatywnym, komunikacji, maszyny niestety często zawodzą. Ludzie i firmy nie mogą w pełni ufać MT.
Istotne jest, że narzędzia te są w stanie stałego rozwoju i doskonalenia. Opublikowane w sierpniu 2022 badanie dotyczące dokładności oprogramowania do AI i tłumaczenia maszynowego wykazało, że narzędzia te są bardziej dokładne w tłumaczeniu tekstu pisanego, niż mogłoby się wydawać - w niektórych przypadkach wymagają zerowej ilości poprawek od profesjonalnych lingwistów. Przeprowadzone przez firmę Weglot i konsultantów językowych Nimdzi badanie oceniało i porównało pięciu wiodących dostawców usług tłumaczenia maszynowego - Amazon Translate, DeepL, Google Cloud, Microsoft Translator i ModernMT (7).

Narzędzia MT zostały przetestowane pod kątem ich dokładności i niezawodności w tłumaczeniu 168 różnych segmentów zawierających ponad tysiąc różnych słów z amerykańskiego angielskiego na francuski, niemiecki, hiszpański, chiński uproszczony, arabski i europejski portugalski. Ocenione przez profesjonalnych lingwistów, 85% z 14 tłumaczeń zostało ocenionych jako "bardzo dobre" lub "akceptowalne", przy czym żaden z materiałów przetłumaczonych maszynowo nie został oceniony jako "bardzo zły".
Spośród 168 różnych segmentów słów testowanych przez oprogramowanie, niemiecki ponownie okazał się najlepszy, z 145 sekcjami niewymagającymi żadnych poprawek ze strony profesjonalnych lingwistów po przetłumaczeniu, w porównaniu do portugalskiego, który miał tylko 58 takich sekcji. Włoski był najtrudniejszym językiem do przetłumaczenia ze średnią akceptowalnością 2,6, podczas gdy niemiecki uzyskał najwyższą ocenę 3,4. Pozostałe wyniki to: hiszpański (3,2), portugalski (3), arabski (3), francuski (2,9) i chiński uproszczony (2,8).
Mówić w swoim języku i być rozumianym

Aplikacje do tłumaczenia językowego różnią się pod względem funkcjonalności i cech, ale generalnie działają przez wykorzystanie funkcji tłumaczenia maszynowego, sprzętu oraz aplikacji urządzenia mobilnego (8). Dodatkowo niektóre aplikacje do tłumaczenia wykorzystują uczenie maszynowe, które polega na wdrażaniu oprogramowania komputerowego, które może uczyć się autonomicznie i stale poprawiać aspekty wydajności, takie jak dokładność. Ważną funkcją, którą należy wziąć pod uwagę przy pobieraniu aplikacji do tłumaczenia, jest wykrywanie języka w czasie rzeczywistym, tłumaczenie w czasie rzeczywistym, rozpoznawanie głosu i rozpoznawanie tekstu, funkcjonalność przy niskiej przepustowości łącza oraz wachlarz dostępnych języków.
Identyfikacja języka w czasie rzeczywistym to możliwość wskazania użytkownikowi aplikacji, w jakim języku jest mówiony lub pisany tekst. Tłumaczenie w czasie rzeczywistym zapewnia tłumaczenie języka w trakcie mówienia lub pisania. Rozpoznawanie głosu umożliwia użytkownikom wypowiadanie słowa lub wyrażenia, które mają zostać przetłumaczone bez zapisywania własnymi rękami.
Funkcjonalność aplikacji do tłumaczenia języków zależy od tego, czy urządzenie mobilne, na którym jest ona zainstalowana, ma łączność. Niektóre aplikacje korzystają z bibliotek do pobrania zawierających powszechnie używane pytania i terminy, co pozwala korzystać z aplikacji offline. Niektóre aplikacje polegają na infrastrukturze telekomunikacyjnej lub Wi-Fi w celu uzyskania dostępu do serwera aplikacji i wykonania tłumaczenia. Inne znów aplikacje wykorzystują zarówno pobraną bibliotekę, jak i połączenie z serwerem.
Tłumaczenie języków w trybie offline zazwyczaj oferuje mniej opcji niż jest to możliwe w przypadku łączności z internetem. Ponadto niektóre aplikacje mają specjalistyczne przeznaczenie, np. medyczne, które skupiają się na wstępnie załadowanych frazach lub pytaniach związanych ze zdrowiem, jak również na funkcjach łączących obrazowanie, rozpoznanie obrazu z tłumaczeniem. Aplikacje tłumaczące języki wykorzystują głośniki urządzeń mobilnych, mikrofony, klawiatury i ekrany, aby umożliwić funkcje tłumaczenia tekstu lub głosu.

Korzystając z większości aplikacji tłumaczeniowych, użytkownicy wprowadzają do aplikacji słowa, które mają zostać przetłumaczone za pomocą tekstu lub głosu, a także wskazują pożądany język wyjściowy. Dane wejściowe są następnie przesyłane do serwera w chmurze, gdzie oprogramowanie aplikacji lub algorytm tłumaczenia maszynowego przetwarza je i tłumaczy. Tłumaczenie jest następnie przesyłane z powrotem do urządzenia w czasie rzeczywistym.
Na rynku dostępne są również inne produkty wyposażone w specjalny sprzęt audio, np. wkładki douszne, zaprojektowane w celu zapewnienia dodatkowych możliwości. Na przykład niektóre urządzenia aktywnie słuchają mowy w innym języku i automatycznie tłumaczą ją na język ojczysty użytkownika bezpośrednio do słuchawki. Taki sprzęt audio jest sparowany z urządzeniem podłączonym do internetu, które wykonuje tłumaczenie. Dodatkowo istnieją systemy translatorów, które zawierają własne platformy do łączenia się z internetem w celu wykonywania tłumaczeń (nie są to aplikacje do pobrania na telefony lub tablety).
Świat, w którym dwie osoby posługujące się różnymi językami, ale nieznające ich wzajemnie, swobodnie "na żywo", bez opóźnień rozmawiają, rozumiejąc wszystko, co mówi interlokutor, dzięki działającemu natychmiastowo, bezbłędnemu systemowi tłumaczenia maszynowego, który działa w tle w sposób dyskretny, jeśli nie w ogóle niezauważalny, jest być może bliższy niż nam się wydaje. Już w tej chwili maszyna może sprawować się lepiej niż próby porozumienia się obustronnie łamaną angielszczyzną przez dwie osoby, dla których mowa Szekspira jest językiem obcym.
Google Translate - produkt największej na świecie firmy internetowej jest najbardziej znanym obecnie tłumaczem maszynowym. Może tłumaczyć tekst na ponad sto języków i jest nawet w stanie tłumaczyć offline w wielu językach (dokładnie 59). Dodatkowo może tłumaczyć tekst i liczby wykonane przez aparat fotograficzny urządzenia lub poprzez analizę zdjęcia lub obrazu wprowadzonego do aplikacji. Funkcja tłumaczenia konwersacji w tej aplikacji pozwala dwóm osobom (mówiącym w różnych językach) komunikować się głosowo za pośrednictwem swoich smartfonów (z zainstalowanym Google Translate), ponieważ ich mowa jest tłumaczona w czasie rzeczywistym.
DeepL - aplikacja oparta na systemie NMT opracowanym przez niemiecką firmę Linguee GmbH (obecnie znaną jako DeepL GmbH). Translator przedstawia się jako "najdokładniejszy tłumacz maszynowy na świecie". Opinię tę podziela coraz większa liczba użytkowników.
Speak & Translate - znana użytkownikom iPhone’a. Może pochwalić się jedną z najwyższych ocen aplikacji tłumaczących w iTunes. Aplikacja zdolna do wykonywania tłumaczeń tekstowych w ok. 120 językach i tłumaczeń mowy w 54 językach. Wykrywa język mówiony.
Microsoft Bing Translator - aplikacja oparta na własnym systemie tłumaczenia maszynowego firmy Microsoft, bazującym na metodzie NMT.
Amazon Translate - aplikacja oparta na stale doskonalonym systemie NMT wyróżnia się funkcją Active Custom Translation, która umożliwia użytkownikom importowanie własnych danych tłumaczeniowych w celu dostosowania tłumaczeń do ich preferencji.
Yandex Translate - stworzona przez rosyjski odpowiednik Google’a aplikacja obsługuje 95 języków w trybie online. W trybie offline może również wykonywać tłumaczenia na język angielski z następujących języków: francuski, niemiecki, włoski, rosyjski, hiszpański i turecki. Jeśli chodzi tłumaczenie mowy, Yandex Translate radzi sobie słabiej, ponieważ obsługuje tylko cztery języki: angielski, rosyjski, ukraiński i turecki.
SYSTRAN Translate - oparty na własnej sieci neuronowej firmy SYSTRAN, która ma długą historię. Założona w 1968 roku należy do pierwszych firm oferujących komercyjne usługi tłumaczenia maszynowego.
TripLingo - aplikacja reklamowana jako doskonałe narzędzie dla osób często podróżujących biznesowo, wyposażona w tłumacz języka mówionego w czasie rzeczywistym. Oprócz możliwości tłumaczenia na 19 języków, aplikacja oferuje rozmówki z tysiącami haseł w 13 językach.
AppTek Speech Translate - umożliwia tłumaczenie między językiem angielskim a ponad czterdziestoma językami
z wykorzystaniem neuronowego tłumaczenia maszynowego, jak również ponad trzydzieści języków w trybie automatycznego rozpoznawania mowy, w tym arabski, chiński mandaryński, holenderski, francuski, niemiecki, hebrajski, włoski, japoński, koreański, perski, rosyjski i hiszpański. Jest to narzędzie płatne.
SayHi Translate - aplikacja tłumacząca, która jest w stanie tłumaczyć za pomocą mowy, mowy na tekst, tekstu na mowę oraz tekstu na tekst. Strona Aplikacja oferuje wykrywanie i identyfikację języka w czasie rzeczywistym podczas online i umożliwia użytkownikom zlecanie tłumaczeń między językami. SayHi Translate nie działa w trybie offline. Dostępne jest tłumaczenie między językiem angielskim a 89 językami i dialektami, w tym arabski, chiński (mandaryński), chorwacki, francuski, hebrajski, włoski, norweski, portugalski, rosyjski, hiszpański, turecki i walijski.
Canopy Speak - to aplikacja specjalistyczna do tłumaczenia zwrotów medycznych. Tłumaczenia w bazie zostały stworzone przez specjalistów medycznych. Są uporządkowane według dziewięciu specjalności. Aplikacja Canopy Speak umożliwia również korzystanie z przycisku wywoływania tłumacza, który łączy użytkownika bezpośrednio z linią tłumacza przez telefon. Aplikacja ta nie oferuje wykrywania lub identyfikacji języka w czasie rzeczywistym i wymaga od użytkownika wybrania języka wejściowego i wyjściowego.
iTranslate Medical - została uruchomiona w odpowiedzi na pandemię wirusa COVID-19, aby umożliwić istniejącym urządzeniom ograniczenie kontaktu tłumaczy z osobami potencjalnie zakażonymi. Aplikacja umożliwia tłumaczenie z mowy na mowę, z mowy na tekst, z mowy na tekst oraz z tekstu na tekst. iTranslate oferuje wykrywanie i identyfikację języka w czasie rzeczywistym, a także pozwala użytkownikowi zlecić tłumaczenie między dwoma językami. Aplikacja jest w pełni funkcjonalna w trybie offline. Dostępne jest tłumaczenie między językiem angielskim a czterema różnymi językami, chińskim, francuskim, niemieckim i hiszpańskim.
Mirosław Usidus